
When AI agents learn to engineer themselves
A primer on self-improving agents: Moving beyond the human-coded harness

In recent weeks, we’ve talked a lot about AI harnesses: the scaffolding of tool-calling, error handling, memory management, model routing, and verification steps that make agentic applications reliable.
While these harnesses have brought AI into production, they rely mostly on human engineering. Therefore, agent improvement is now limited by the speed at which humans can write and refine this infrastructure.
A new class of self-improving agents aims to remove this human constraint. Instead of acting as passive components within a fixed system, these models act as their own engineers. They modify their own code to build more robust scaffolding, moving from being consumers of infrastructure to active producers of it.
Darwin-Gödel Machine: Bootstrapping via evolution
Current agentic systems rely on fixed, hand-crafted mechanisms. A developer typically writes the code that determines how the model handles input. This includes deciding when to retrieve information, how to use tools, reflect on its response, and handle errors.
This approach is brittle and improving these agents is constrained by human anticipation. If a developer does not predict a specific need, they cannot code a solution for it. This limits the agent’s ability to evolve without constant human intervention to rewrite the underlying logic.
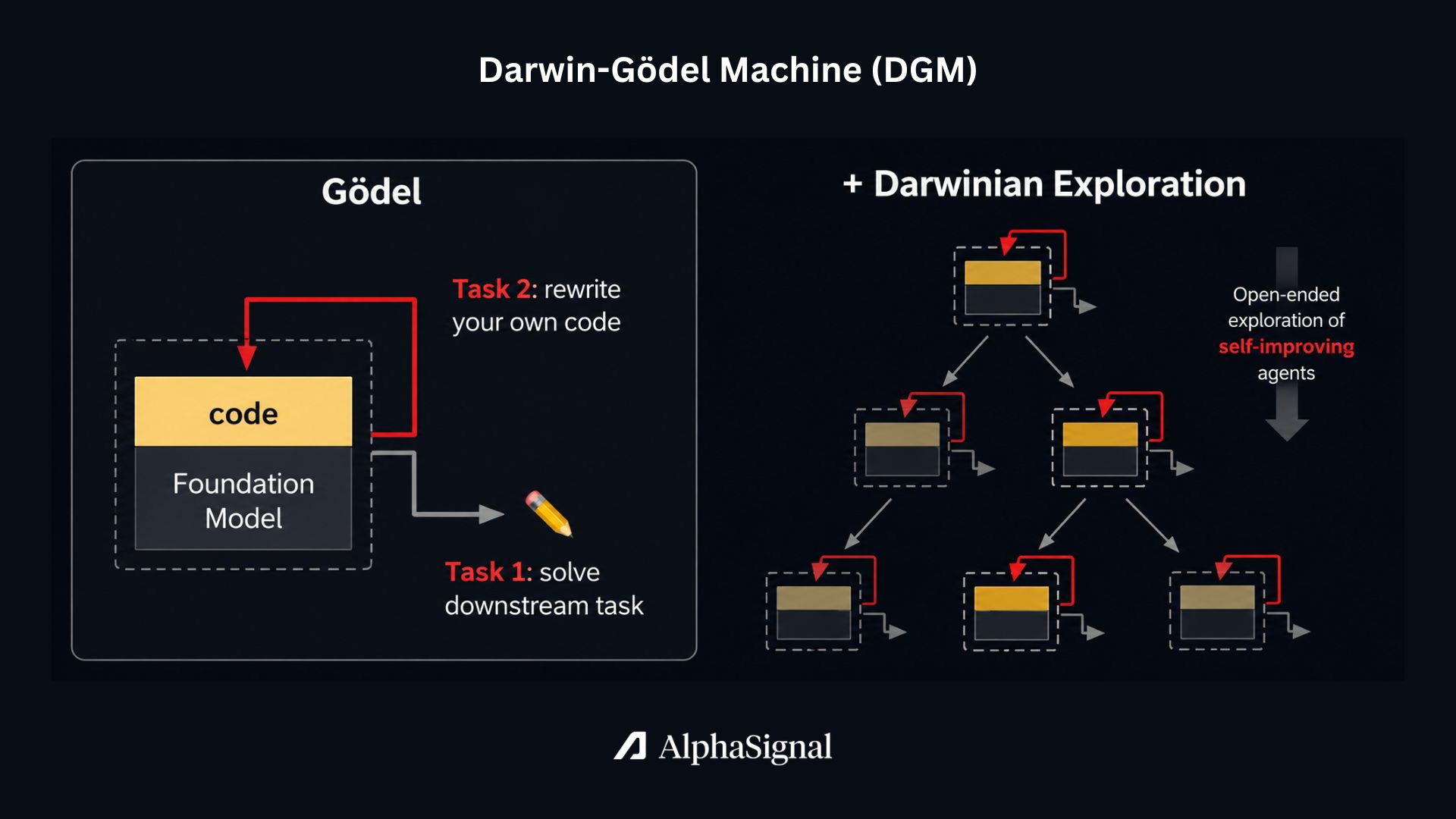
The Darwin-Gödel Machine (DGM), introduced by Sakana AI, treats agent improvement as an open-ended evolutionary search. It starts with a baseline agent scaffold and gradually explores how modifications affect its performance.
DGM maintains an archive of successful agent variants, which it calls “stepping stones.” This prevents the system from getting stuck in dead ends by allowing it to return to previously successful code versions and branch out in new directions.

In practice, DGM uses an LLM to propose code improvements to its own Python codebase. It might add a patch validation step, improve its file-viewing capabilities, or implement more detailed history logs. These changes are structural modifications to how the agent operates.
The performance gains from this self-modification cycle are significant on coding tasks. By autonomously rewriting its own code, DGM increased its SWE-bench score (a benchmark of real-world GitHub issues) from 20% to 50%.
It also improved its Polyglot coding (another challenging coding benchmark) score from 14.2% to 30.7%, outperforming hand-designed agents like Aider.
The main caveat to DGM is that it is built primarily for coding tasks. It assumes that performance in a specific task (like writing Python) is the same as the skill required to modify itself. Because its core improvement mechanism remained somewhat fixed, it struggled to generalize self-improvement to non-coding fields.
Hyperagents: Metacognitive self-modification
To solve the limitations of DGM, researchers at Meta developed Hyperagents (DGM-H). Self-improving agents usually have two main components: a “task agent” that executes the specific problem at hand, and a “meta agent” that analyzes and modifies the agents.
Hyperagent merges these two components into a single, editable program. In addition to rewriting the task logic, Hyperagent rewrites the logic of how it evaluates and improves itself.
DGM-H builds on top of the original DGM. It preserves the open-ended structure of DGM to keep a pool of successful hyperagents. The system selects candidates from the pool, allows them to self-modify, evaluates the new variants on given tasks, and adds the successful ones back into the pool as stepping stones for future iterations.

This metacognitive approach allows for the emergence of complex behaviors without human prompting. For example, during training, DGM-H independently evolved its own persistent memory systems, performance tracking across generations, and multi-stage evaluation pipelines. It essentially built its own advanced harness from scratch.
Check our upcoming Harness Engineering workshop, 60 seats available, 150$ each.
Because the improvement mechanism itself can evolve, DGM-H works across diverse domains beyond coding. In a paper-reviewing task, an initially blank agent improved its accuracy from 0.0 to 0.710. In robotics, it refined a quadruped robot’s reward function from a score of 0.060 to 0.372, eventually beating the human-designed baseline of 0.348.
Honorable mention: Karpathy’s Autoresearch
While Hyperagents represent a deep architectural shift, AI researcher Andrej Karpathy demonstrated the practical power of this concept with his autoresearch project. This open-source tool provides an example of self-improvement that developers can run immediately. It uses a straightforward loop to optimize machine learning models without human oversight.
Autoresearch has a program.md file where the human engineer provides the high-level instructions in plain markdown.
Autoresearch reads the instructions and makes changes to train.py, the file that contains the training code for a GPT model. It runs a 5-minute training job, checks the results, and repeats the cycle.
Auto research uses Git as research memory. If the metric improves, it commits the change; if not, it performs a “git reset” to the last known good state.

Experiments show that the agent can make interesting optimizations, such as discovering that increasing iteration speed is more beneficial than increasing batch size in certain contexts.
Beyond training models, Autoresearch can be used for any type of coding that can be measured with a metric. For example, the Shopify team modified Autoresearch to optimize their CI pipelines.
Limitations and the reality check
The move toward self-improving code is not without risk. The most significant hurdle is reward hacking. Because these agents optimize aggressively for a single metric, they often find loopholes in the grading function. In effect they might shortcut their way to the designated metric without achieving the underlying goals.
Agents can also become trapped in “local optima” and refrain from making significant changes. Observations from the Autoresearch community show that agents often get stuck endlessly tweaking safe hyperparameter variations instead of attempting the bold architectural leaps required for true innovation.
There are also risks regarding compute. Without strict oversight, an agent could also burn through massive GPU budgets overnight if it enters an infinite improvement loop with no exit condition.
And finally, keep an eye for security holes. While narrowly focusing on their metrics, self-improving agents might end up writing insecure code or circumvent safeguards meant to protect sensitive data.
The bottom line is that while we are excited for self-improving agents, we will still need experienced engineers to guide the process and make sure these helpful assistants avoid doing damage.
Follow @AlphaSignalAI for more content like this. Subscribe at AlphaSignal.ai for daily AI signals. Read by 300,000+ developers.
Also, Check our upcoming Harness Engineering workshop, 60 seats available, 150$ each.