
What Claude’s 1M Token Context Window Unlocks for Developers
What a million-token context window actually means for codebases, debugging, and real developer workflows.


Anthropic has now rolled out its 1 million token context window as a general-availability feature for both Claude Opus 4.6 and Claude Sonnet 4.6.
The release matters for three reasons:
The full 1M window is now available at standard pricing
Full rate limits apply across that window
Media limits have expanded to 600 images or PDF pages per request.
Anthropic also says Claude Code users on Max, Team, and Enterprise plans now get that full Opus 4.6 window by default.
So what does that actually mean for developers?
Laravel educator Povilas Korop pulled off something that would have been unrealistic just six months ago. He loaded his project specification, every model, every migration, every route, and the rest of the app context into Claude on a $100/month Max plan.
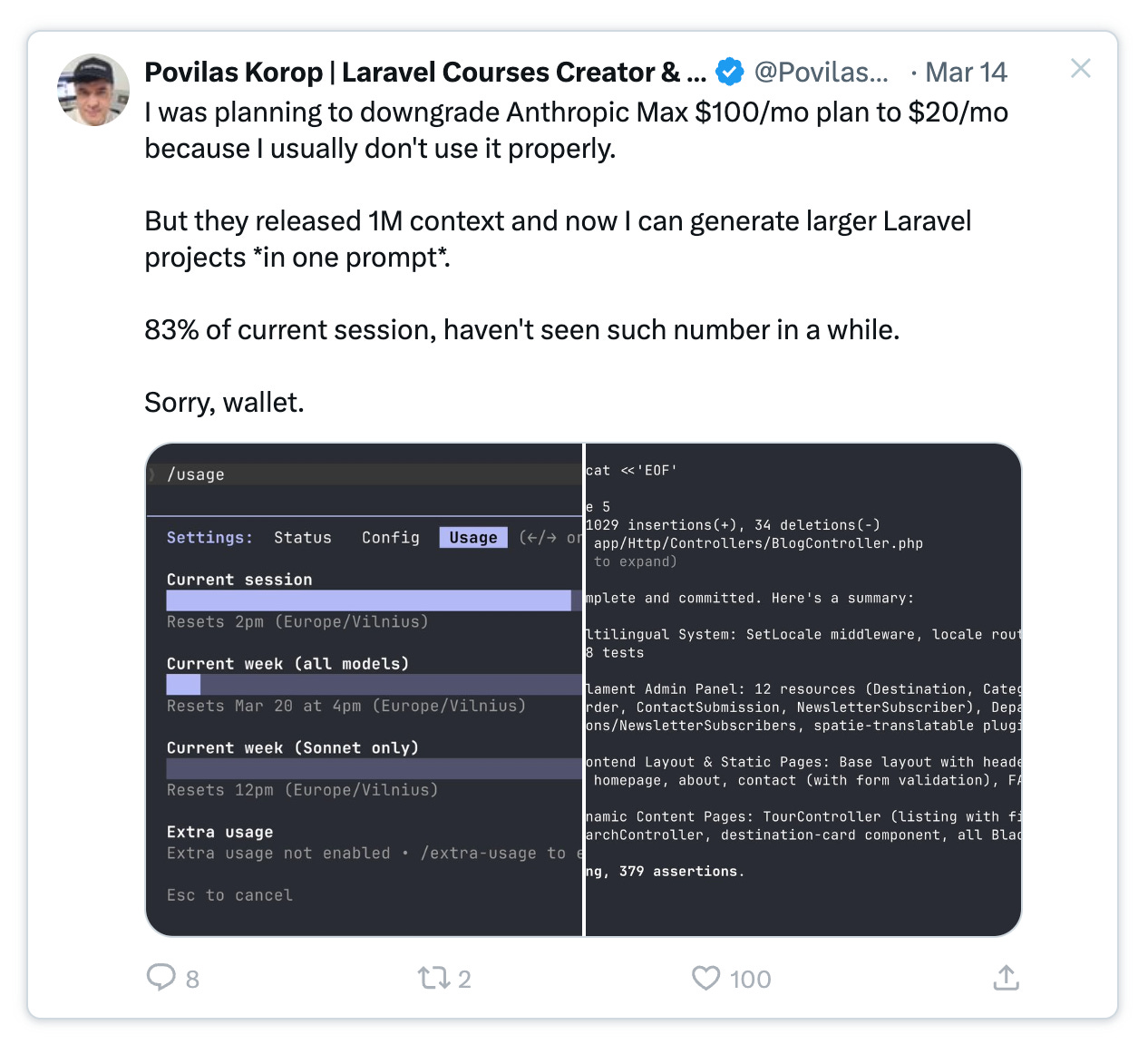
The context utilization meter climbed to 83%.
One prompt. One window. The entire project sitting in memory at once.
But the context window increase is just part of the story. By now, nearly every frontier LLM company can claim roughly a million tokens of context. What matters more is what happens when you actually use that much room, and what the tradeoffs look like when the bill arrives.
Thanks for reading! Subscribe for free to receive new posts and support my work.
Tokens, explained without the jargon
If you’ve heard people casually throw around the word “tokens” and just nodded along, here’s the simple version.
A token is a chunk of text. Not quite a full word, and not just a character either. It lives somewhere in between. Think about how a child sounds out a word like “unbelievable.” They don’t process it as one block. They break it apart.
Un. Be. Liev. Able.
Language models do something similar. They split text into smaller pieces that are statistically useful for understanding and prediction.
In English, one token is often about three-quarters of a word on average. “Hamburger” might become two tokens. “I” is one token. A short email might land around 200 tokens. A page of a novel is often somewhere near 300.

Code consumes tokens faster than prose does. Variable names, punctuation, indentation, comments, braces, imports. A single Python file can get expensive in token terms faster than a page of plain writing. A 500-line TypeScript file might cost you around 2,000 tokens before you’ve even asked the model to do anything.
So when someone says “1 million tokens,” it helps to translate that into something more tangible: roughly 750,000 words. Think ten novels, or one huge codebase.
The context window is the model’s working memory. Your prompt, your attached files, the running conversation history, and the model’s replies all share that same finite budget. Once you hit the limit, the model either starts dropping earlier material or can’t continue cleanly.
Claude Code and the end of “sorry, I forgot”
Before this, long Opus sessions would eventually hit a wall. Somewhere around 150K to 200K tokens, the system would trigger what Anthropic calls a compaction event.
Earlier conversation history would get summarized and compressed to free up space. In practice, that meant you could be halfway through a refactor and suddenly the model would lose track of a file it had already read or a decision made a few turns earlier.
Anthropic says Opus 4.6 with 1M context leads to fewer compactions in Claude Code, and in its announcement it quoted Codeium’s CPO Jon Bell saying they’d seen a 15% decrease in compaction events.
The company also quoted Anton Biryukov describing how Claude Code can spend 100K+ tokens just searching Datadog, Braintrust, databases, and source code before it even begins proposing a fix.
The model reads your code. Then it reads your monitoring stack. Then your tests. Then your database schema. Then it comes back to the code with all of that information still active in memory. Every one of those steps burns tokens.
With a 200K ceiling, you could hit the limit before the investigation was even done. With 1M, the investigation and the fix can live in the same working session.
That doesn’t necessarily make the model smarter. But it does make it less forgetful, and in a real coding workflow that can matter just as much.
For Claude Code users on Max, Team, and Enterprise, Anthropic says Opus 4.6 now defaults to the full 1M context automatically.
Anthropic also says the GA release is available through the Claude Platform and major cloud providers including Amazon Bedrock, Google Cloud Vertex AI, and Microsoft Foundry. For enterprises already committed to a specific cloud, that reduces lock-in concerns.
Thanks for reading! Subscribe for free to receive new posts and support my work.
Can it actually use all that context?
A million tokens sounds impressive, but can the model still perform well across that entire window? Or does quality fall apart near the edges?
Anthropic reports a 78.3% score on MRCR v2, a benchmark for tracking facts and entities across long contexts, and says that’s the highest among frontier models at that context length.
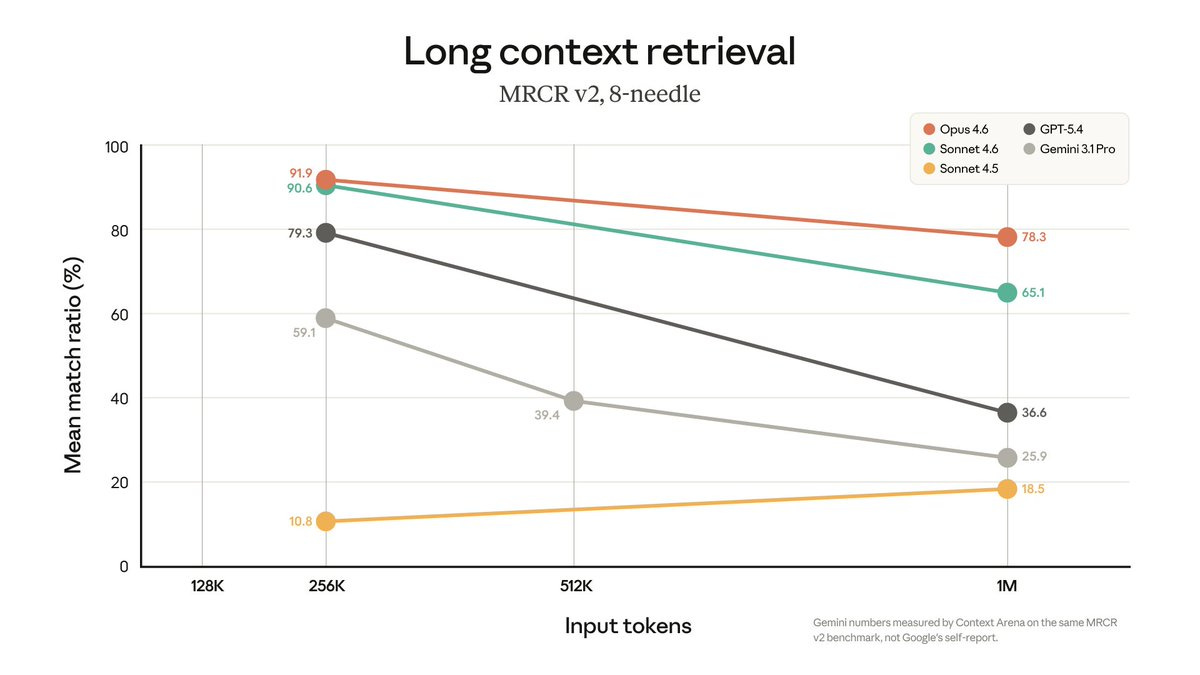
Benchmarks are useful, but practical performance is the real test.
Can the model find a function definition buried 600K tokens deep?
Can it remember a constraint you mentioned forty messages earlier?
The honest answer is that all long-context models still degrade at extreme lengths. Attention over huge windows is hard. Content near the beginning and the end tends to be recalled more reliably than information buried in the middle.
That limitation is often described as the “lost in the middle” problem.
So no, the problem hasn’t disappeared.
What has changed is that Anthropic appears to have pushed the degradation curve farther out. In practical terms, Opus 4.6 at 500K tokens feels more usable than earlier long-context systems did at much shorter lengths. The last slice of the window is still less reliable than the first slice, but the useful zone is clearly larger.
Caveats worth keeping in mind
First, input and output are separate budgets. The million-token limit applies to the input side: your prompt, your files, and your conversation history. Output is separate, and it’s capped lower. You’re not going to get a 500K-token response, nor would you want one.
Second, just because you can use 1M tokens doesn’t mean every request should. If you’re asking a simple syntax question, loading your whole repository is overkill.
Third, be deliberate about structure. Prompt caching helps a lot, but caching strategy still matters, and so does placement. The most important material shouldn’t be buried halfway through a giant prompt if you can help it.
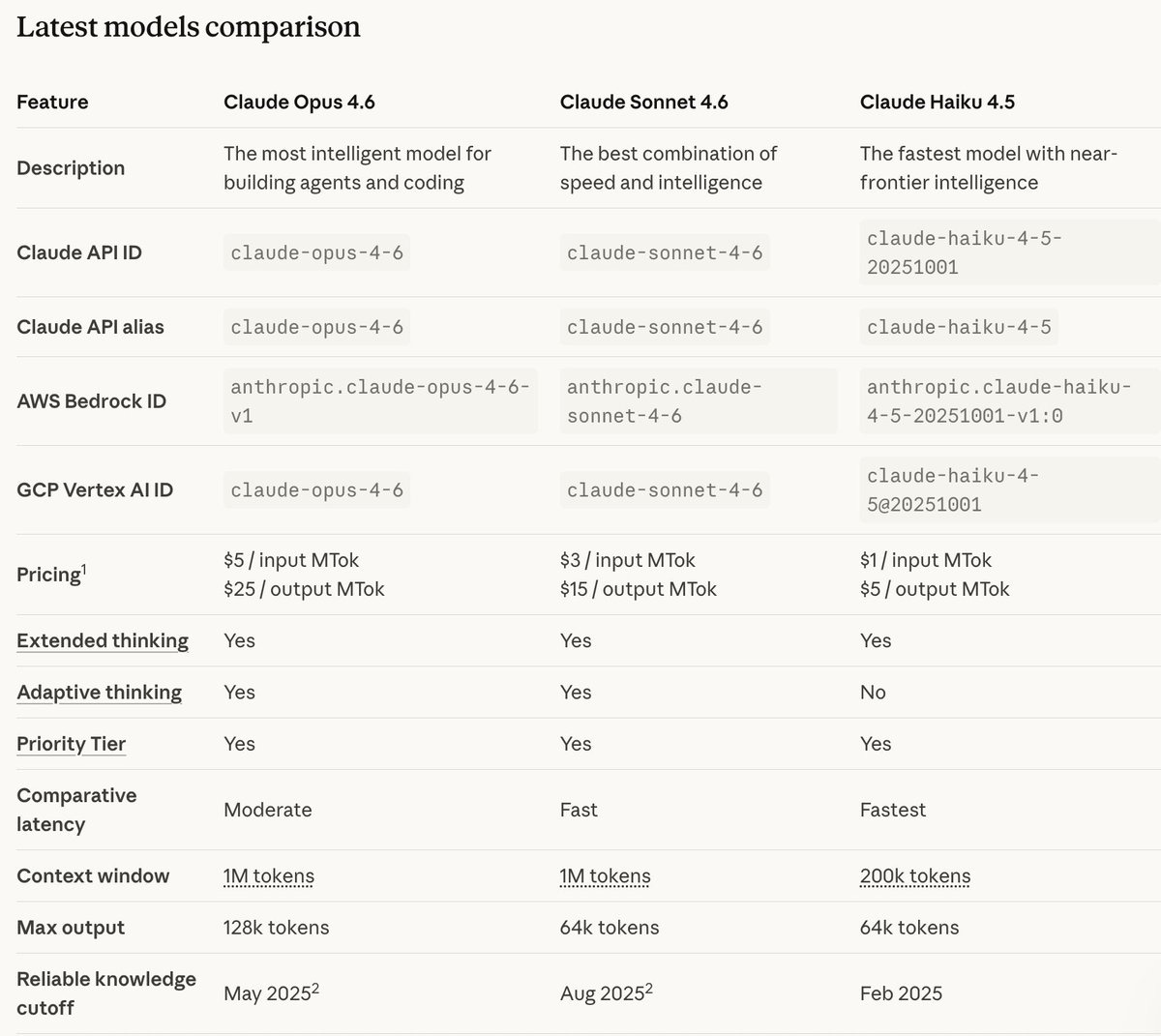
If you don’t need Opus-level reasoning, Sonnet 4.6 is worth serious attention. It offers the same 1M context window at a lower price point.
Haiku, by contrast, still tops out at 200K context, which is fine for ordinary interaction but not really built for full-codebase work.
For context, this is how the Claude models compare:
Thanks for reading! Subscribe for free to receive new posts and support my work.
References:
1M context window blog: https://claude.com/blog/1m-context-ga
Claude model pricing: https://platform.claude.com/docs/en/about-claude/pricing
Claude model comparison: https://platform.claude.com/docs/en/about-claude/models/overview
Join 250k+ developers staying ahead in AI. We curate the latest models, repos, and research — so you don’t miss what matters: AlphaSignal.ai