
Stop Asking Whether the Agent Worked. Ask What the Harness Observed
Your agent passed, and that tells you almost nothing. Inside: the trace, the failure map, and the scorecard that do.


In 5 minutes, you will learn why the final answer is the wrong thing to grade, the eight-layer trace that makes a run debuggable, and how to pin a failure on one harness layer before you trust the next run.
Two agents close the same ticket. The final answer says they tied. The final answer is lying to you.
One closed it in four steps, ran the full test suite, and asked before it touched production. The other looped eleven times, skipped the suite, and slammed into a permission wall it never mentioned.
Same diff. Same green check. Two completely different runs, and an output-only evaluation can see only the checkmark.

Most devs/teams still grade agents the way they grade a chatbot. That worked when the model only talked. It breaks the moment the model starts acting.
For a chatbot, the output is the product, so scoring the output is fair.
But for an agent, the output is a receipt. It confirms the transaction closed and says almost nothing about what got touched, retried, skipped, or carried by luck.
The research is starting to say this with numbers. Harness-Bench, a new diagnostic benchmark, ran 5,194 agent trajectories across 106 sandboxed tasks and found that the same task and model can land very differently depending on the harness wrapped around them.
A blunt companion paper, “Stop Comparing LLM Agents Without Disclosing the Harness”, argues that for long, hard tasks the harness moves performance more than the choice of model does.
Why the final answer lies
An agent’s final output is a compression of everything it did. Compression deletes exactly the part you need when something breaks.
One green “pass” can hide at least four different problems.
A coding agent ships a patch that clears the single test it ran and never touches the broader suite. Green check, latent bug.
A research agent cites the perfect source, but it got there through a stale memory entry that happens to still be right. Next month it will not be.
A support agent resolves a ticket after quietly trying a refund path it was forbidden to use and getting denied. Nobody upstream ever hears about the attempt.
A long-running agent finishes a multi-day job after three rounds of context compaction, and no one can say which of the starting assumptions made it through the last handoff.
All four score as wins. Output-only evaluation tells you the task passed. It never tells you which layer made the pass fragile, or whether the next run will be as lucky.
The shift the research is making
Harness-Bench stopped ranking models and started ranking model-and-harness pairs. It crosses 8 model backends with 6 harnesses, and on every one of those 5,194 runs it logs four things: the final artifact, the full execution trace, the usage stats, and what the validators returned.
The final artifact is the smallest item on that list. The benchmark also catalogs the failure symptoms that keep recurring, which is the useful part. Once you can name the symptom, you can hunt for the layer that caused it.
“Stop Comparing LLM Agents Without Disclosing the Harness” is harsher about the status quo. Its Binding Constraint Thesis holds that once models reach frontier-class parity, the harness explains more of the performance gap than the model, so any leaderboard that hides its harness is quietly handing the model credit for the scaffolding’s work.
Anthropic makes the operational version of the argument in its agent-evaluation writing: grade the trajectory and the outcome as two separate things. The transcript of tool calls, token counts, turns, latency, and state checks is a grading surface in its own right, not a footnote under the final reply.
Stack the three together and the direction is obvious. The question is moving from “did the model answer?” to “what did the model and the harness do together?”
The harness telemetry stack
Answering that question takes a trace, and a trace has layers. Here is the minimum set that lets you rebuild a run after it breaks, with the failure each layer exists to catch.
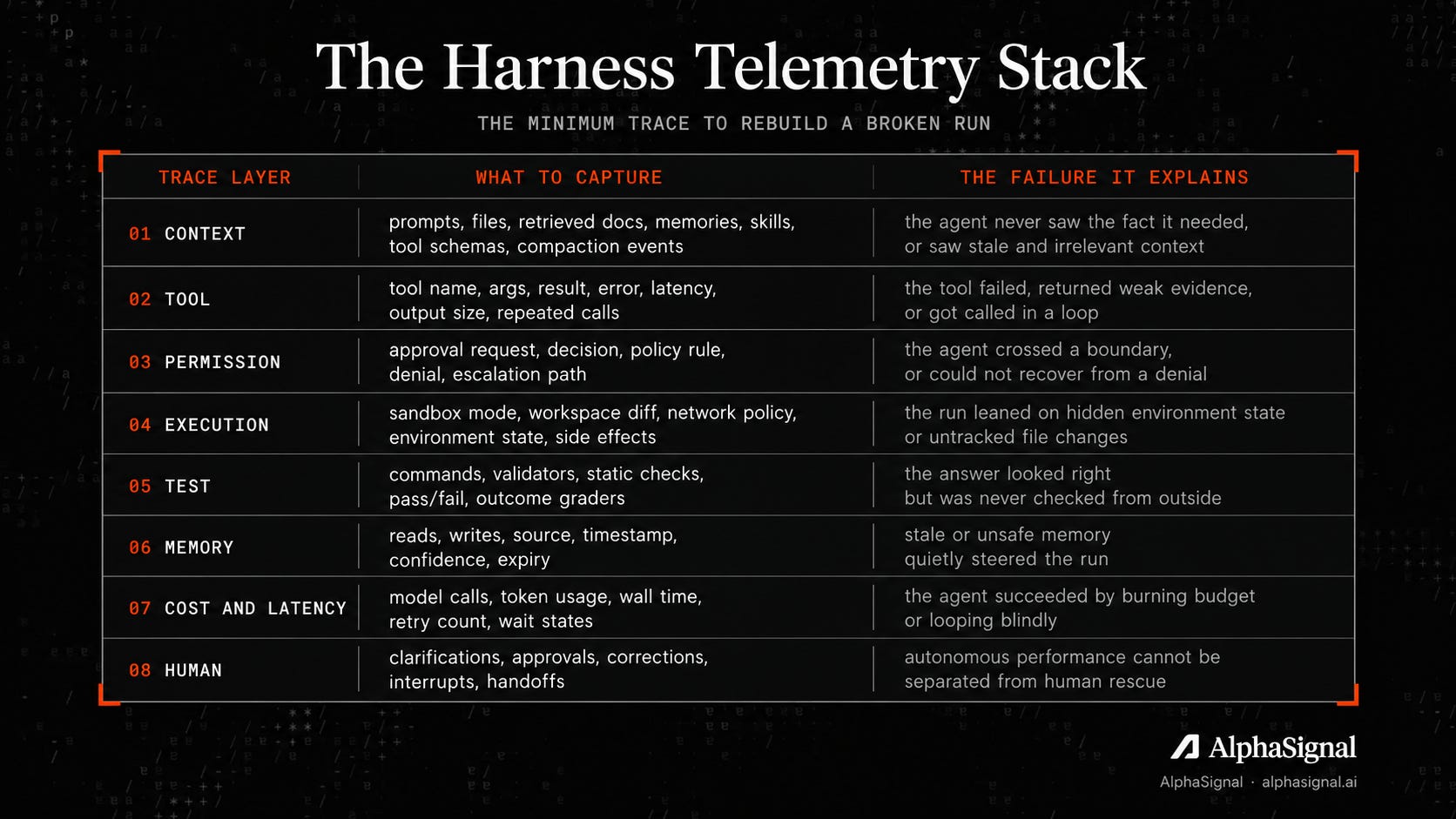
This is not a dashboard wishlist. It is a debugging contract. When a layer is missing from the trace, the failure that lives in that layer cannot be attributed, and you are back to rerunning the agent and squinting.
Codex and Claude Code already emit parts of this over OpenTelemetry: model and tool calls, sessions, token and cost metrics, and structured logs, with traces already shipping on Codex and still in beta on Claude Code. The plumbing is starting to exist. The rare part is treating the trace, not the answer, as the thing you actually review.
A failure map, not a tutorial
With the trace in hand, a broken run finally produces a useful question: which layer failed?
The eleven harness layers everyone lists make a mediocre tutorial and a sharp failure map. Stop reading them as “what a harness contains” and start reading them as “where to point when the answer came out wrong.”

The map does one thing well. It turns “the agent failed” into “the governance layer failed,” which is the difference between a shrug and a fix.
The four agents here split into two shapes. Coding agents like Codex and Claude Code pour their engineering into governance, execution, and verification, because their failures hit files, terminals, repos, and CI. Personal agents like Hermes and OpenClaw pour theirs into memory, identity, channels, and continuity, because their failures play out across time, people, and messaging apps.
Both need traces. They just need the densest tracing in different layers.
Then there is the harder case. When a personal agent runs a coding agent as its backend, which Hermes and OpenClaw can both do, the trace has to cross the seam between two harnesses. The outer agent knows what it asked for. The inner runtime owns the real tool calls, diffs, tests, and permission decisions. If your trace stops at the handoff, so does any hope of explaining the failure.
The harness reliability scorecard
The trace shows what happened. Judging it needs a rubric you run after every important run, before you trust the next one.
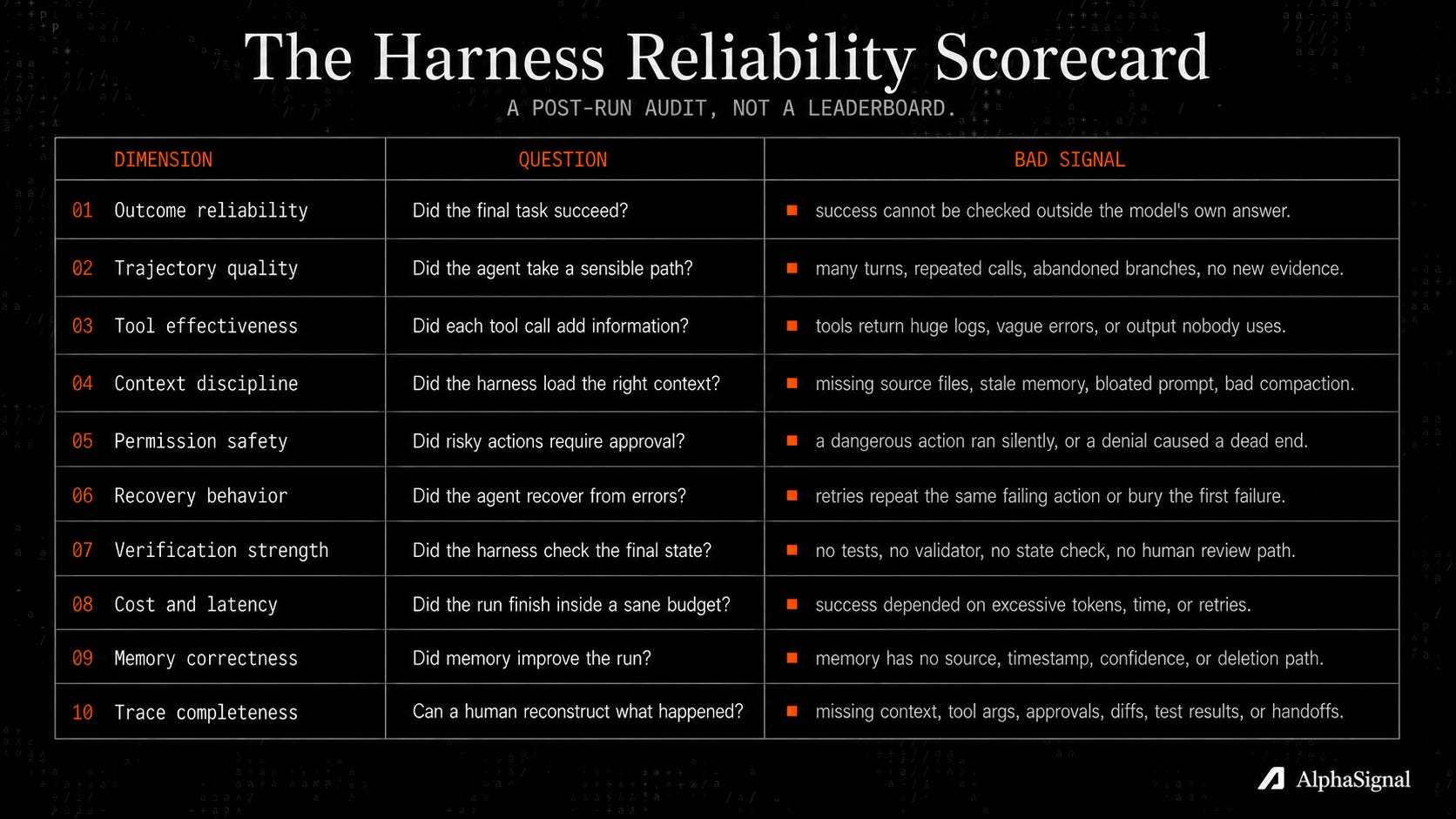
This is not a leaderboard. It is a post-run audit, and its only job is to make a failure local enough to fix.
Run it honestly and most “working” agents lose points on trace completeness first. You cannot grade what you never recorded. A run that passed but trips four of these signals is not a success. It is a success you got away with, and got-away-with does not survive contact with production.
The model can tell you what it answered. The trace tells you what actually happened.
So the reliability question for agents has changed. It is no longer “did it work?” It is whether the harness saw enough to explain the run on the day it doesn’t.
Which layer in your stack is flying without a trace right now: context, permissions, memory, or verification?
All Sources in first reply. Full breakdown of recent updates + daily signals in our newsletter (link in bio).
Appendix
All Tables as markdown format.
Table 1:
| Trace layer | What to capture | The failure it explains |
|---|---|---|
| Context | prompts, files, retrieved docs, memories, skills, tool schemas, compaction events | the agent never saw the fact it needed, or saw stale and irrelevant context |
| Tool | tool name, args, result, error, latency, output size, repeated calls | the tool failed, returned weak evidence, or got called in a loop |
| Permission | approval request, decision, policy rule, denial, escalation path | the agent crossed a boundary, or could not recover from a denial |
| Execution | sandbox mode, workspace diff, network policy, environment state, side effects | the run leaned on hidden environment state or untracked file changes |
| Test | commands, validators, static checks, pass/fail, outcome graders | the answer looked right but was never checked from outside |
| Memory | reads, writes, source, timestamp, confidence, expiry | stale or unsafe memory quietly steered the run |
| Cost and latency | model calls, token usage, wall time, retry count, wait states | the agent succeeded by burning budget or looping blindly |
| Human | clarifications, approvals, corrections, interrupts, handoffs | autonomous performance cannot be separated from human rescue |Table 2:
| Harness layer | The question to ask when the run fails |
|---|---|
| Control | Did the agent have the right rules, success criteria, and boundaries? |
| Context | Did the harness load the right information, at the right time, without stale or distracting material? |
| Runtime loop | Did the loop stop, retry, compact, and resume correctly? |
| Tools | Did the tool interface return compact, accurate, actionable observations? |
| Execution | Did the action run in the intended workspace, sandbox, network mode, and environment? |
| Governance | Did risky actions require approval, and did denials leave a recoverable path? |
| Memory | Did durable memory help the run, or inject old, unsafe, or untraceable assumptions? |
| Skills | Did the agent pick the right procedure, version, and validation steps? |
| Planning | Did planning reduce uncertainty, or spawn abandoned branches and noisy handoffs? |
| Verification | Did the harness check the final state instead of only the final message? |
| Interface | Were human approvals, clarifications, and interrupts captured as part of the run? |Table 3:
| Dimension | Question | Bad signal |
|---|---|---|
| Outcome reliability | Did the final task succeed? | success cannot be checked outside the model's own answer |
| Trajectory quality | Did the agent take a sensible path? | many turns, repeated calls, abandoned branches, no new evidence |
| Tool effectiveness | Did each tool call add information? | tools return huge logs, vague errors, or output nobody uses |
| Context discipline | Did the harness load the right context? | missing source files, stale memory, bloated prompt, bad compaction |
| Permission safety | Did risky actions require approval? | a dangerous action ran silently, or a denial caused a dead end |
| Recovery behavior | Did the agent recover from errors? | retries repeat the same failing action or bury the first failure |
| Verification strength | Did the harness check the final state? | no tests, no validator, no state check, no human review path |
| Cost and latency | Did the run finish inside a sane budget? | success depended on excessive tokens, time, or retries |
| Memory correctness | Did memory improve the run? | memory has no source, timestamp, confidence, or deletion path |
| Trace completeness | Can a human reconstruct what happened? | missing context, tool args, approvals, diffs, test results, or handoffs |
Sources
Harness-Bench: Measuring Harness Effects across Models in Realistic Agent Workflows: https://arxiv.org/abs/2605.27922
Stop Comparing LLM Agents Without Disclosing the Harness: https://arxiv.org/abs/2605.23950
Anthropic, Demystifying evals for AI agents: https://www.anthropic.com/engineering/demystifying-evals-for-ai-agents
OpenTelemetry, GenAI observability: https://opentelemetry.io/blog/2026/genai-observability/
Claude Code, observability with OpenTelemetry: https://code.claude.com/docs/en/agent-sdk/observability
Codex, configuration reference (OpenTelemetry trace, metrics, and log exporters): https://developers.openai.com/codex/config-reference