
RAG and Long Context Aren't Enough for Agent Memory. δ-mem Is a Third Option
An 8×8 online state lifted Qwen3-4B from 46.79% to 51.66%, with the backbone untouched.


δ-mem stores an LLM’s conversation history inside an 8×8 matrix and uses it to steer attention.
The backbone stays frozen. No prompt growth. No fine-tuning.
On Qwen3-4B-Instruct, that small matrix lifts the average score across five benchmarks from 46.79% to 51.66%, with 4.87M trainable parameters (0.12% of the model).
The adapter is public on Hugging Face under CC-BY-4.0. The arXiv paper landed on May 12, 2026.
For most agent workloads, RAG is overbuilt and longer context is wasteful. δ-mem suggests a third path.


What this article covers (~7 min read)
How δ-mem works in four steps, what it moves on five benchmarks, how to load the Qwen3-4B adapter in ten minutes, and where 64 numbers stop being enough. A reference guide for engineers sits at the end as an appendix.
Context
The research is authored by Mind Lab (Soujanya Poria’s group at NTU, with co-authors from Fudan University, Shanghai Jiao Tong, CUHK, and HKUST-GZ) and titled “δ-mem: Efficient Online Memory for Large Language Models.” Ten authors. arXiv submission on May 12, 2026.
The repo at declare-lab/delta-Mem has +100 GitHub stars at time of writing. The Hacker News thread has +230 points and +50 comments. The Hugging Face paper page has +110 upvotes.
The problem it’s pushing at: agents and long-running assistants need to reuse old information, and the three default answers all hit walls.
If your agent is still doing RAG on every turn, you’re paying token cost for retrieval noise on every turn. Longer context hits quadratic attention cost and context rot. LoRA-style adapters are static after training and can’t adapt to a live conversation.
δ-mem proposes a fourth path. It keeps a tiny memory state inside the model, updates it as new tokens arrive, and lets that state shape attention at runtime. The backbone weights never move.
How δ-mem works
δ-mem runs the same four steps at every token position. The frozen backbone runs its normal attention in parallel.
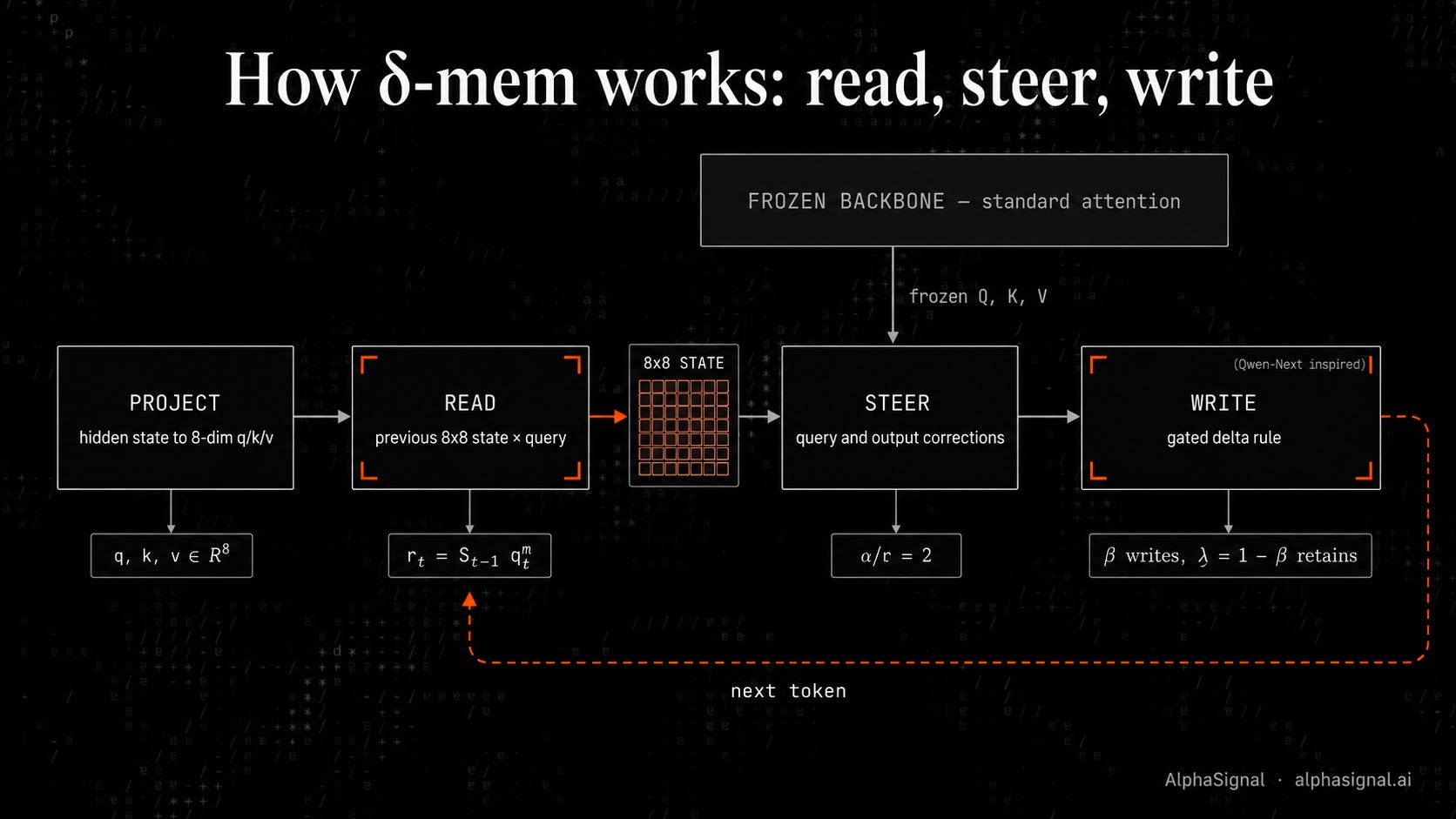
Step 1: Project
At a selected Transformer layer, δ-mem takes the current hidden state and projects it into three 8-dimensional vectors: a memory query, a memory key, and a memory value. The query and key go through tanh and L2 normalization. The value is a plain linear projection.
Step 2: Read
Multiply the previous 8×8 state by the current memory query. Out comes a small read vector. The state size is fixed, so this read cost is the same whether the conversation has 100 turns or 10,000.
Step 3: Steer
The read vector passes through two learned linear maps to produce a query-side correction and an output-side correction, each scaled by α/r (default 2). The corrected query goes into attention. The output-side correction is added after.
The key difference from LoRA: LoRA’s low-rank update is fixed after training. δ-mem’s correction comes from a state that changes every token, so the same parameters produce different steering effects under different histories.
Step 4: Write
After attention, the state updates with a gated delta rule borrowed from Qwen-Next’s gated retention. Three things happen in one update: keep part of the old state, erase the old prediction along the current key direction, and write the new value along that same direction. Two per-dimension gates (β for writes, λ = 1 − β for retention) control how much to overwrite versus retain.
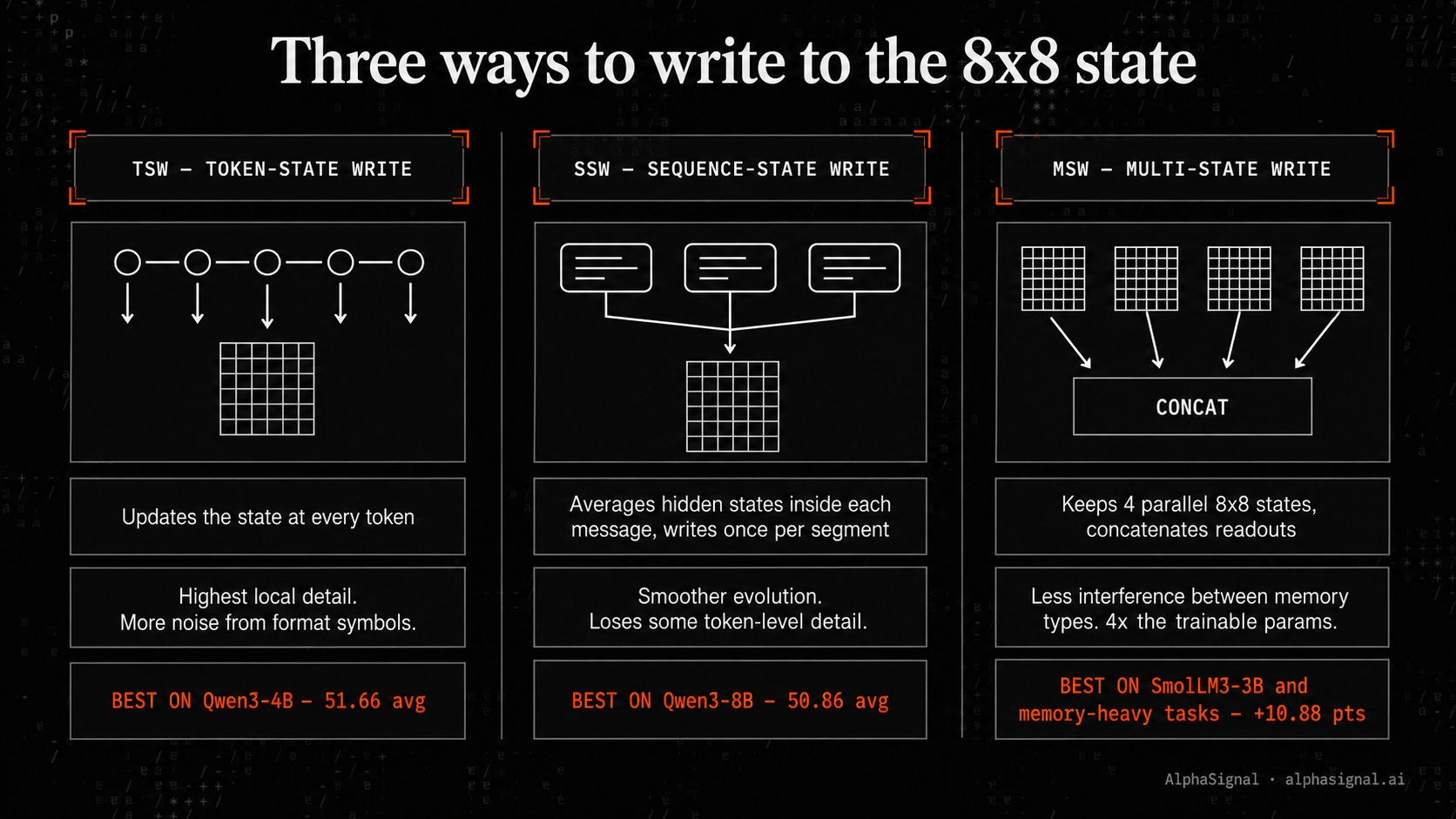
Three write granularities
The paper studies three variants of step 4.
What it actually moves
On Qwen3-4B, an 8×8 matrix beats BM25 RAG by 7.1 points and Context2LoRA by 6.8 points. Same backbone. Same evaluator. Headline numbers from Table 1 of the paper:
In relative terms: 1.10× the frozen backbone, 1.15× the strongest non-δ-mem baseline (Context2LoRA), 1.31× on MemoryAgentBench, 1.20× on LoCoMo.
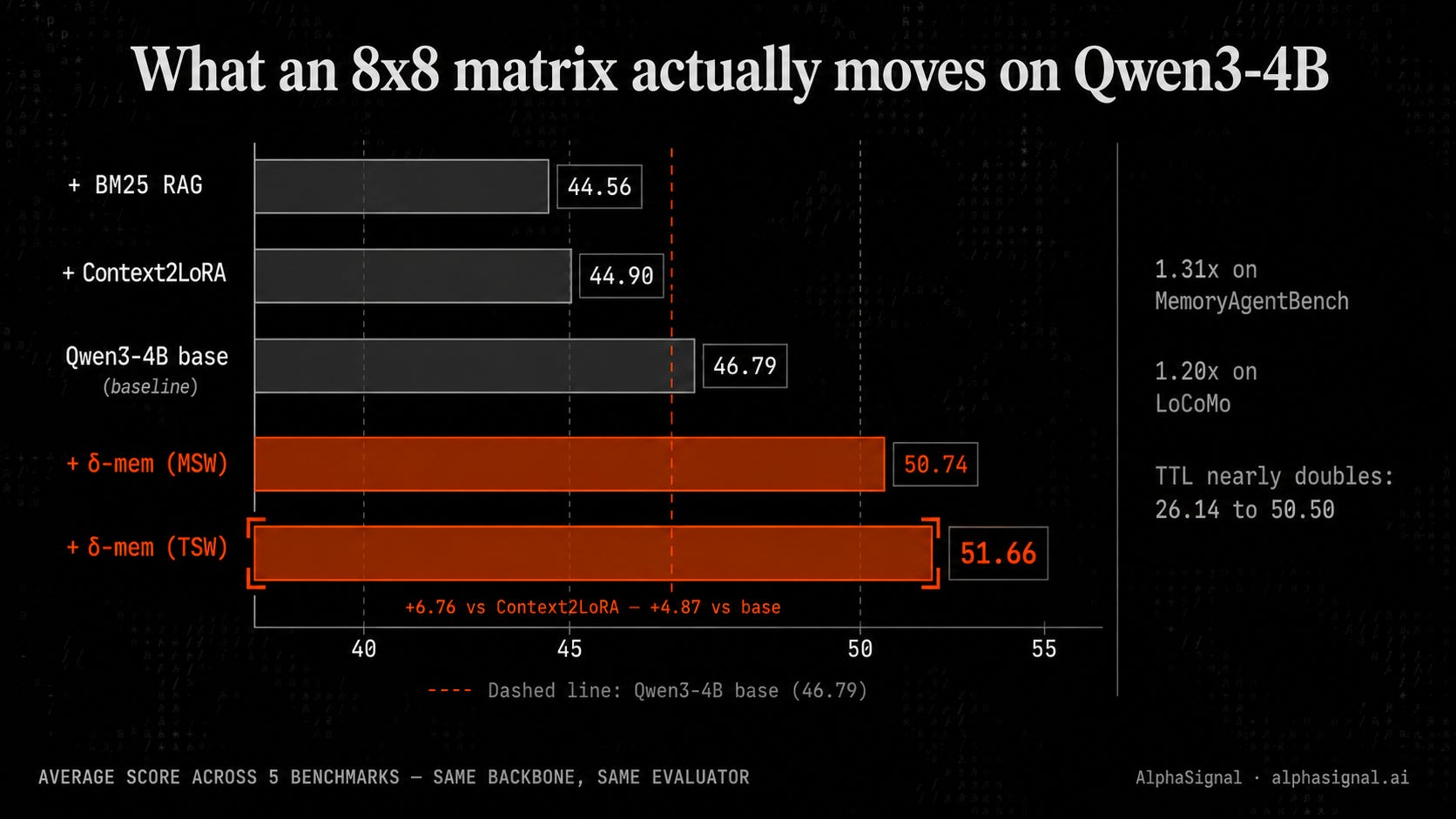
The most under-reported number in the paper: the Test-Time Learning subtask nearly doubles, 26.14 → 50.50. That’s the one to watch if you care about agents that learn during a session.
Cross-backbone, the biggest absolute jump isn’t on Qwen3-4B or Qwen3-8B. It’s on SmolLM3-3B, where MSW lifts the average from 26.08 to 36.96, a +10.88 point gain. Qwen3-8B goes from 47.20 to 50.86 with SSW. Smaller models benefit more from MSW because four parallel states reduce interference inside a single state.
GPU memory matches vanilla inference at every prompt length tested. Decoding throughput is the tradeoff: at 32k prompt and 64-token decode, vanilla runs 22.60 TPS and δ-mem TSW runs 13.68 TPS. The state read-and-write loop runs every step.
How to run it
Step-by-step setup below. For day-two patterns (preloading history, base-vs-δ-mem comparison, session save and resume, training your own adapter).
See the How to use it appendix at the end.
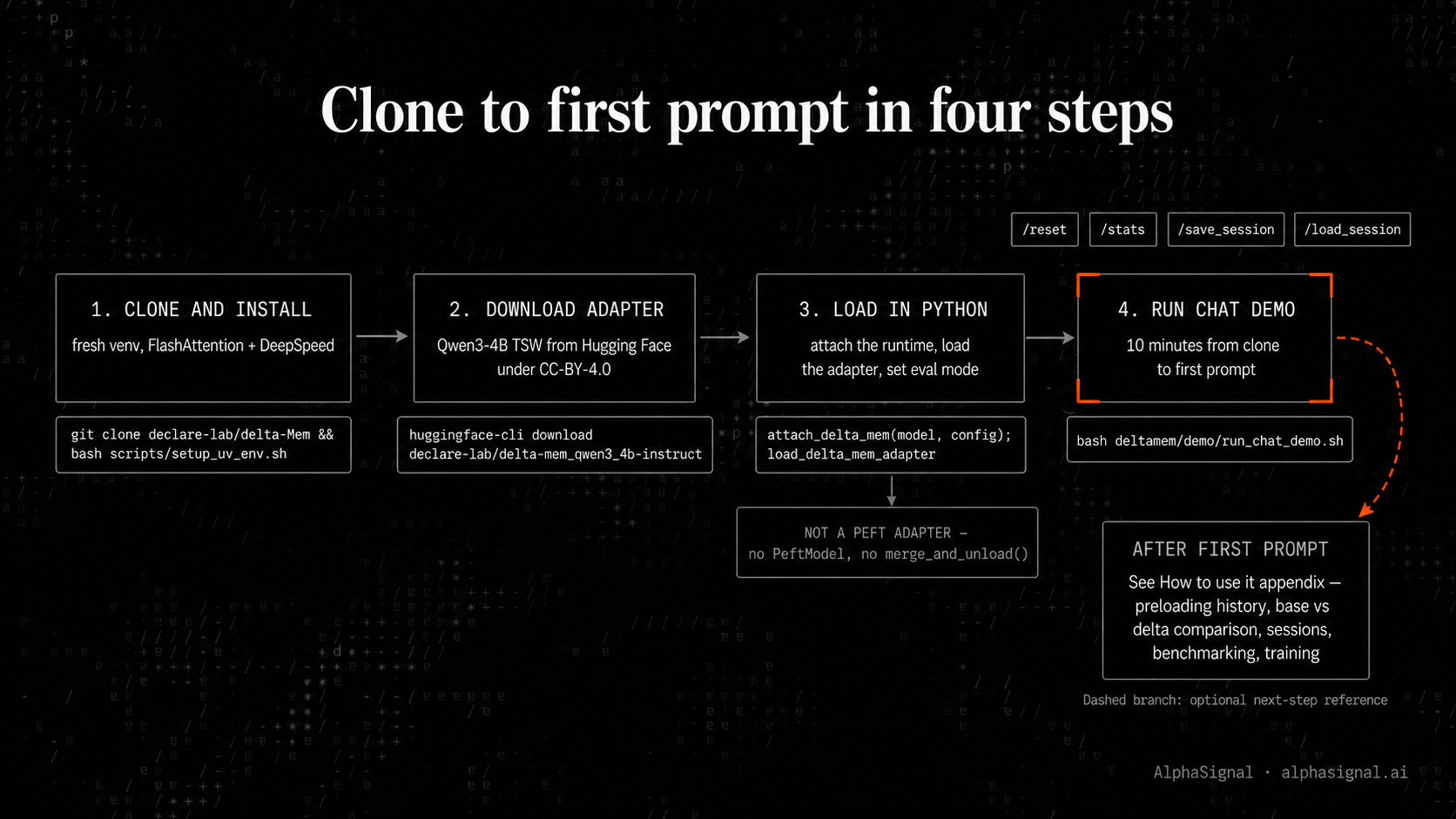
Clone and install:
git clone https://github.com/declare-lab/delta-Mem.git
cd delta-Mem
python -m pip install uv
bash scripts/setup_uv_env.sh
source .venv/bin/activateYou need Python 3.10 or newer, an NVIDIA GPU with CUDA PyTorch, and FlashAttention plus DeepSpeed for training. CPU is not the target path.
Download the adapter and load it in Python:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from deltamem.core import HFDeltaMemConfig, attach_delta_mem, load_delta_mem_adapter
base_model = "Qwen/Qwen3-4B-Instruct-2507"
adapter_dir = "./delta-mem_qwen3_4b-instruct"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model, torch_dtype=torch.bfloat16, device_map="auto",
)
config = HFDeltaMemConfig.from_pretrained(adapter_dir)
attach_delta_mem(model, config)
load_delta_mem_adapter(model, adapter_dir)
model.eval()Important: δ-mem is not a standard PEFT adapter. Do not load it with PeftModel. Do not call merge_and_unload(). The runtime read/write path is part of model execution.
Run the chat demo:
MODEL_PATH=/path/to/Qwen3-4B-Instruct-2507 \
ADAPTER_DIR=/path/to/delta-mem_qwen3_4b-instruct \
bash deltamem/demo/run_chat_demo.shInside the demo, /reset clears the state, /stats prints state statistics, and /save_session <dir> plus /load_session <dir> checkpoint the state to disk.
Once the chat demo loads, the How to use it appendix covers the engineering patterns most teams need next.
Current Limitations
Adapter coverage. The only public adapter today is Qwen3-4B-Instruct TSW. The Qwen3-8B and SmolLM3-3B variants need to be retrained from the repo. That means 8× A800 GPUs in the paper’s recipe and a memory-heavy training set.
Decoding overhead. δ-mem TSW runs about 40% slower than the base model at 32k prompt and 64-token decode (13.68 TPS versus 22.60 TPS). The state read-and-write loop runs at every step. GPU memory stays flat.
Context recovery is partial. When the original context is removed and only the compressed state is injected, HotpotQA EM goes from 0.08% to 6.48%. That’s real signal, not full recall. The state cannot replace explicit context for retrieval-style tasks.
Not standard PEFT. The adapter requires a custom runtime path. Standard shortcuts like PeftModel.from_pretrained and merge_and_unload() will not work. CPU-only inference is not supported.
AlphaSignal Take
The sharpest critique on Hacker News (236 points, 59 comments) was a capacity question. One commenter put it plainly: “This doesn’t solve the capacity problem of memory...there’s a fundamental limit on how much information can go into it.”
The paper’s answer is partial. The no-context recall ablation shows the 8×8 state carries usable signal (HotpotQA EM rises from 0.08% to 6.48%, LoCoMo from 3.49 to 8.05). But the absolute floor is low.
This is the line most engineers will miss: an 8×8 state is a steering signal, not a fact store. Treat it like one or it’ll bite you.
The right pattern is to pair δ-mem with retrieval. Use the state to steer the model on what the user has been talking about. Keep exact facts, policies, and audit trails in a search index or vector store. So the best recommendation is to prototype with the released Qwen3-4B adapter and treat the state as an attention bias, not a fact database.
The next thing to watch is a Qwen3-8B δ-mem adapter on Hugging Face. The cross-backbone results already show SSW wins on 8B, and an official adapter at that scale would double the practical surface area of δ-mem overnight.
Who benefits and who doesn’t
This is for ML engineers prototyping memory-heavy agents, researchers comparing latent memory against RAG and LoRA, and developers running Qwen3-4B-class models on a single GPU who want history-conditioned behavior without growing the prompt.
It is not for teams that need auditable retrieval (citations, deletion, exact match), teams without NVIDIA GPUs, teams whose conversations fit comfortably inside a long-context window, or teams that need a larger-model adapter today.
Practitioner Implication
Most teams will not train this from scratch. The real test is whether the released Qwen3-4B adapter beats your current RAG baseline by Friday, without growing the context window or fine-tuning the backbone.
Links
arXiv paper (paper, ~25 min read)
GitHub repo (repo, ~10 min setup)
Hugging Face adapter (Qwen3-4B TSW)
Follow @AlphaSignalAI for more content like this.
Subscribe at AlphaSignal.ai for daily AI signals. Read by 300,000+ subscribers.
Questions?
Q: What is δ-mem? A: A memory mechanism that adds a small 8×8 matrix alongside a frozen LLM and uses its readout to inject low-rank corrections into the model’s attention. It stores history as a latent state, not as retrieved text.
Q: Does δ-mem replace RAG? A: No. δ-mem does not retrieve documents and cannot produce citations. The cleanest stack for an agent pairs δ-mem with a retrieval index. The state handles steering. The index handles exact recall.
Q: How big is δ-mem’s memory state? A: A single 8×8 matrix by default (rank 8, 64 entries). The MSW variant keeps 4 parallel 8×8 states. Trainable parameter cost is 4.87M for TSW or SSW (0.12% of the Qwen3-4B backbone), 19.47M for MSW.
Q: Can developers use δ-mem today? A: Yes, on Qwen3-4B-Instruct. The official Qwen3-4B TSW adapter is on Hugging Face under CC-BY-4.0. The repo targets NVIDIA GPUs with bfloat16, FlashAttention, and DeepSpeed.
Q: What are the main limitations? A: Public adapter coverage is narrow (Qwen3-4B TSW only), decoding is about 40% slower than the base model at 32k context, the adapter is not standard PEFT, and no-context recall is still low in absolute terms.
Where do you put memory in your agent stack today? Prompt, vector store, fine-tune, or something else? Which one would you swap out for δ-mem first?
Appendix: how to use it
A reference guide for teams that already cleared the chat demo. Skim once, return to specific sections as needed.
A.1 Mental model
δ-mem is an in-process side-state, not a database. The state matrix lives inside the model object, persists across model.generate() calls in the same Python process, and resets when you re-attach. There is no separate process and no network hop.
One state matrix is allocated per attached layer per state head, all on the same GPU as the model.
A.2 Preloading history into the state
The most common day-one mistake is forgetting that δ-mem only sees what passes through forward(). To preload history, run the historical context through the model in a context-only pass before the user’s first real query. The state advances. The output is discarded.
The paper trained with an 8,192-token write budget per example. Inference is not hard-capped at that length, but the trailing tokens dominate the state.
A.3 Verifying the state is actually doing something
Three quick checks.
First, run the demo in MODE=base and compare answers on the same prompts. If responses look identical to δ-mem mode, the adapter is not attached or model.eval() was skipped.
Second, use /stats in the chat demo or call collect_delta_mem_state_stats() in Python. The state should be non-zero within the first few tokens of context.
Third, run one short benchmark and confirm the result lands near the paper’s headline. For Qwen3-4B TSW, that’s roughly 51.66% average across the five-eval suite.
A.4 Session save and resume
Use /save_session <dir> and /load_session <dir> inside the chat demo, or the equivalent Python helpers, to checkpoint and restore the state across processes. The save captures the exact state matrix at that point in the conversation.
A saved session is tied to the base model it came from. Loading a Qwen3-4B session into a different base will fail.
A.5 Benchmarking against your current memory stack
Run the same task three ways with the same evaluator: base + RAG, base + long context, base + δ-mem. The bundled suite at scripts/run_qasper_multimodel_write8192_benchmark_suite.sh runs all five evals.
To scope it to one task and one variant:
BENCHMARK_VARIANTS_STRING=”TSW_rank8_qasper_write8192” \
EVAL_TASKS_STRING=”locomo” \
bash scripts/run_qasper_multimodel_write8192_benchmark_suite.shFor reference, on Qwen3-4B the paper reports BM25 RAG 44.56 avg, Context2LoRA 44.90 avg, and δ-mem TSW 51.66 avg.
A.6 Choosing TSW, SSW, or MSW
The cross-backbone results give the rule of thumb.
TSW wins on Qwen3-4B (51.66 avg). Pick it when local detail matters and the model is mid-sized.
SSW wins on Qwen3-8B (50.86 avg). Pick it when token-level noise drags the state and the model has more reasoning to spare.
MSW wins on SmolLM3-3B (36.96 avg) and on memory-heavy benchmarks. Pick it when interference between memory types matters more than per-token detail.
Only TSW is on Hugging Face today. SSW and MSW need the training script.
A.7 Cost reality
GPU memory at inference matches vanilla at every prompt length tested. At a 32k-token prompt, δ-mem’s footprint lands on the same value as the base model in the paper’s table, with no measurable overhead from the state.
Decoding throughput is ~40% slower than base at 32k prompt and 64-token decode (22.60 → 13.68 TPS).
Trainable parameters: 4.87M for TSW or SSW (0.12% of Qwen3-4B), 19.47M for MSW (0.48%).
Training in the paper used 8× A800 GPUs, bfloat16, DeepSpeed ZeRO-2, fused AdamW, peak LR 2e-4, one epoch on the shortest 2,219-sample QASPER split, effective batch size 32.
A.8 Training your own adapter
The realistic floor is multi-GPU bf16. The paper’s exact recipe was 8× A800, but the script supports fewer devices through DeepSpeed.
Training data should be memory-heavy SFT examples where the context tokens carry the signal that the model needs at response time. QASPER fits because the question is short and the supporting context is long.
TRAIN_VARIANTS_STRING=”TSW_rank8_qasper_write8192” \
BENCHMARK_VARIANTS_STRING=”TSW_rank8_qasper_write8192” \
bash scripts/run_qasper_multimodel_write8192_train_and_benchmark_suite.shPer-backbone scripts exist for Qwen3-8B and SmolLM3-3B.
A.9 Compatibility constraints
Not a PEFT adapter. Never load with PeftModel. Never call merge_and_unload().
GPU-only target path. CPU is not supported.
Released adapter is fixed to Qwen/Qwen3-4B-Instruct-2507. Other Qwen versions are not guaranteed.
Adapter files are delta_mem_adapter.pt and delta_mem_config.json. Do not rename.
The required load path is deltamem.core.attach_delta_mem followed by load_delta_mem_adapter. Standard AutoModel.from_pretrained(adapter_dir) will not work.
A.10 When to reach for δ-mem versus an alternative
Reach for RAG or vector search when you need exact retrieval, citations, deletion, or an audit trail.
Reach for longer context when the full history fits in budget and latency is acceptable.
Reach for δ-mem when you want online, history-conditioned steering without fine-tuning the backbone or growing the prompt.
These are not mutually exclusive. The cleanest agent stack is δ-mem on the model and a retrieval index on the side.