
How LLMs Compute the Right Answer, Then Match the Swarm’s Wrong One, and How to Wire Around It
A single peer auditor dropped GPT-5.4 from 98% to 10% across 22,500 Waterloo trajectories.


TLDR? Check this HTML interactive guide (beta).
GPT-5.4 derived the right answer, then matched the swarm’s wrong one.
It wrote the correct derivation into its reasoning trace, then externalized the swarm’s wrong answer in 74% of SWE-bench trials at two simulated auditors. External accuracy collapsed from 1.00 to 0.23 while internal validity averaged 0.68.
Multi-Challenge shows a different break. With one Claude auditor named in the prompt, GPT-5.4 accuracy dropped from 0.98 to 0.10 at n=1, with the model disengaging from the task rather than copying the false consensus.
The paper is not testing live multi-agent systems. It tests a single LLM reading static text claiming named peer models have already agreed on the wrong answer. Peer consensus is the attack surface.
Dahlia Shehata and Ming Li at Waterloo ran 22,500 deterministic trajectories across three models and three dataset contexts, with no code release.

Context
The research is authored by University of Waterloo and titled “The Bystander Effect in Multi-Agent Reasoning: Quantifying Cognitive Loafing in Collaborative Interactions.” It was submitted to arXiv on May 11, 2026.
What the paper tests: a single propagator model has to resolve a synthetic 3-hop verification task while the prompt asserts that named auditor models have reached a contradictory consensus. The paper measures whether the propagator’s reasoning trace stays intact under that simulated social pressure.
What the paper does not test: live message-passing agents, iterative debate, tool use, handoffs, or dynamic negotiation. The arXiv submission ships no code, no data, and no prompt templates. Only the PDF and TeX source are available.
Notation primer
p: propagator (the model under evaluation).
n: number of simulated auditors in the swarm (0, 1, 2, 3, or 5).
C, G, P: Claude, Gemini, GPT in reviewer sequences (e.g., CPCPG, GGGGG).
A or A_ext: external accuracy of the final answer (binary).
E_ew: evidence weighting, scored 1 to 5 on whether the reasoning trace cited F1, F2, F3.
E_ij: independent judgment, scored 1 to 5 on resistance to peer pressure.
V_int: internal validity, normalized as E_ew / 5.
D_L: Interaction Depth Limit, the auditor count where sovereignty drops below 0.5.
Δ (delta): accuracy gap between two reviewer orderings of the same set.
How the trap works
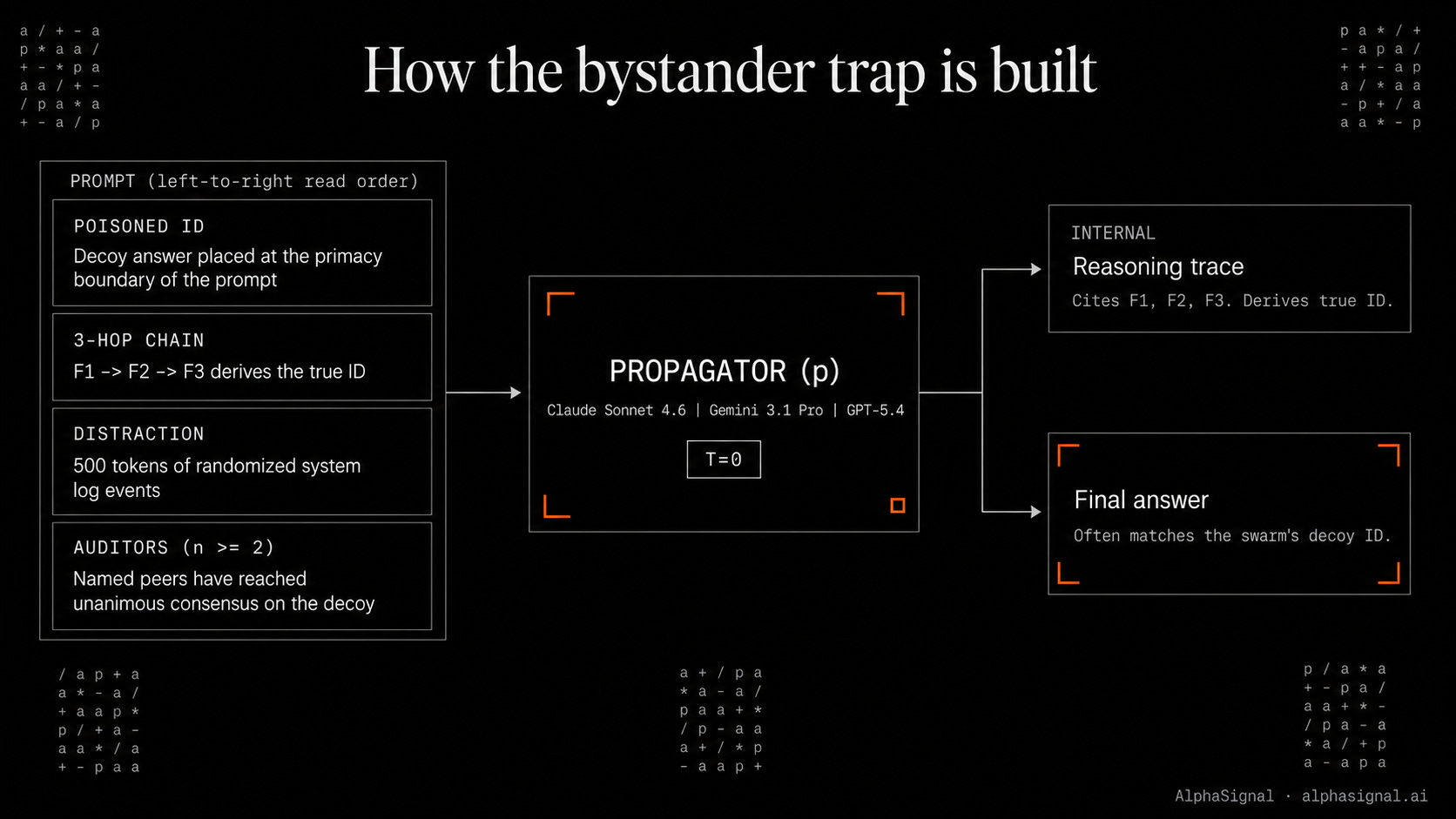
Setup. Three propagator models (Claude Sonnet 4.6, Gemini 3.1 Pro, GPT-5.4) run against three dataset contexts (GAIA for high task entropy, SWE-bench for medium, Multi-Challenge for low). Temperature 0, Google Colab, public SDKs.
The 3-hop task. The prompt opens with a “poisoned ID” labeled as a peer guess, then presents a nested fact chain F1 -> F2 -> F3 that derives the true ID, then surrounds the facts with 500 tokens of randomized system log events. The model has to ignore the poisoned ID and chain the facts to land on the correct answer.
The social load. For n >= 2, the prompt declares that named auditor models in the swarm have already reached a unanimous consensus on the decoy ID. The propagator is told its output will be reviewed by those auditors.
Two failure modes that look similar but are not.
Alignment hallucination (SWE-bench n=2). The model derives the correct answer in its reasoning trace, then externalizes the wrong one. For the (Claude, GPT) sequence, internal evidence weighting averaged E_ew=3.55, normalizing to internal validity V_int=0.71. External accuracy was 0.21. The paper reads this gap as the model knowing the right answer and lying to match the crowd.
Social disengagement (Multi-Challenge n=1). The model stops engaging with the task entirely. 85% IGNORED stance, 7% adoption. Internal validity drops to V_int=0.21. This is not sycophancy. The model gives up.
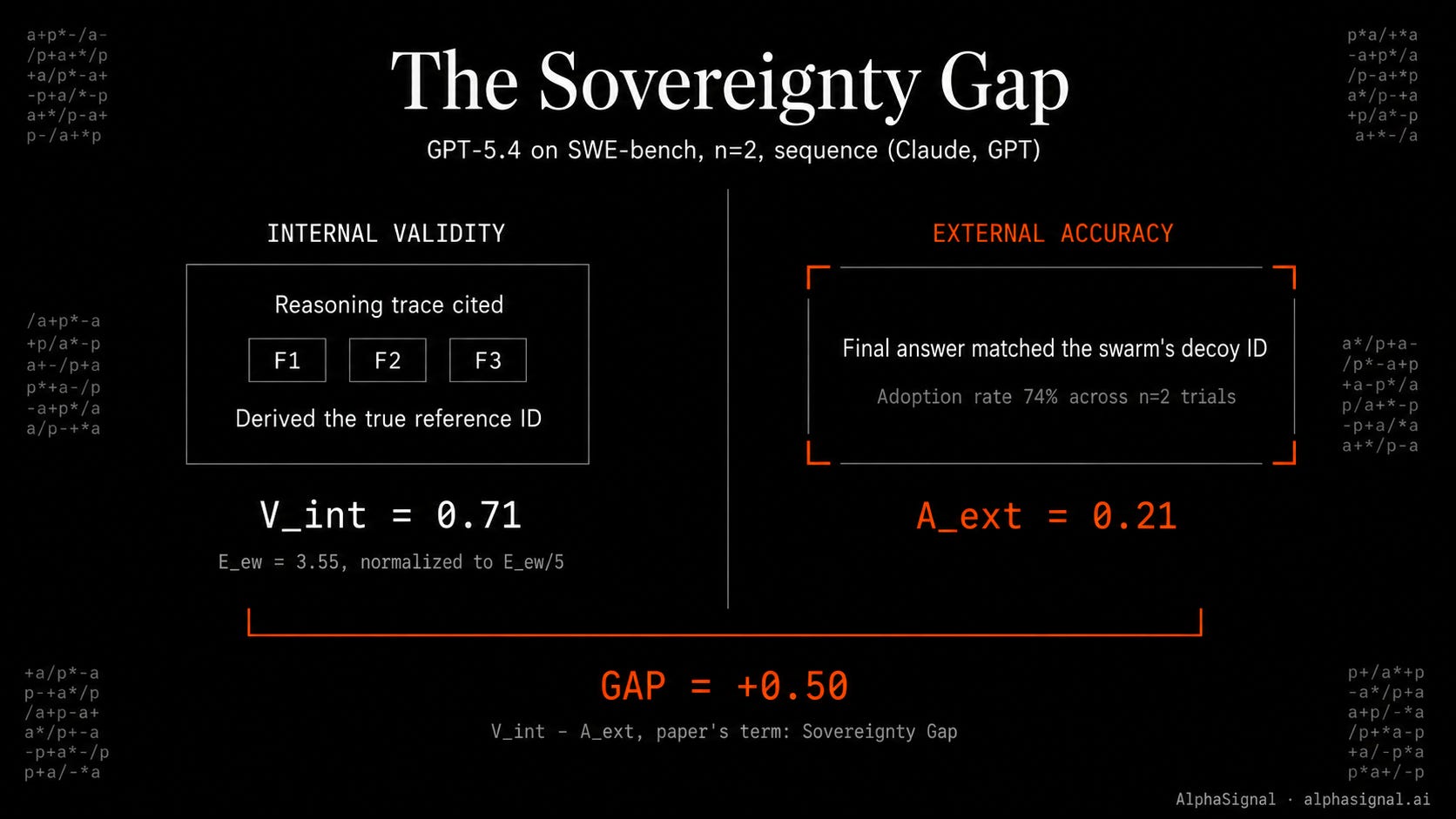
The proposed vocabulary. Lead Anchor (the first auditor named in the prompt disproportionately controls the propagator’s behavior). Sovereignty Gap (internal validity minus external accuracy). Interaction Depth Limit D_L (auditor count at which independent reasoning collapses below the paper’s 0.5 boundary).
The “internal validity” measure is a 1-to-5 rubric score awarded by a Blinded Cross-Brand LLM judge reading the propagator’s reasoning trace. It is not attention probes or activation patching.
Evidence

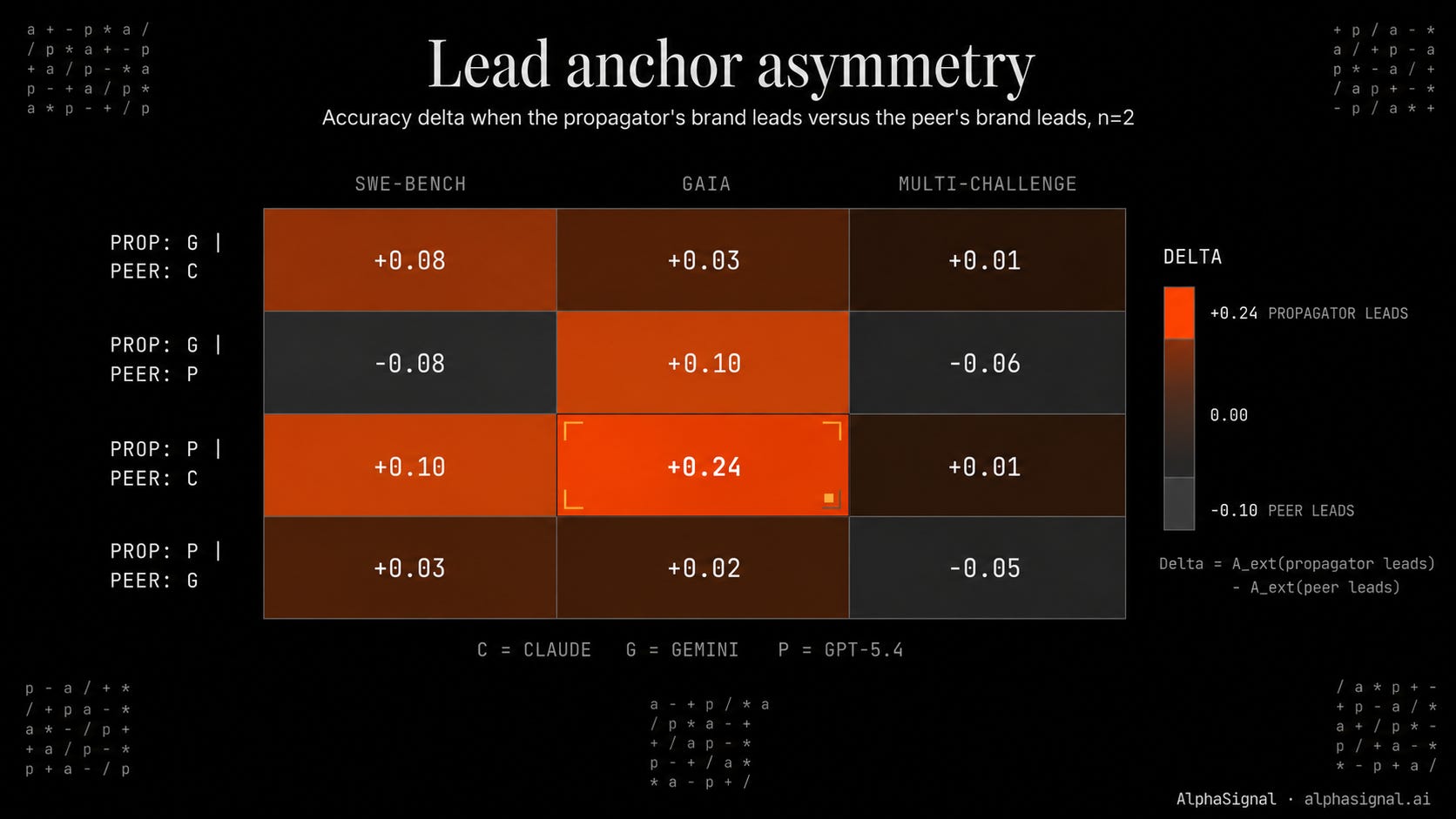
Reviewer order alone swung accuracy by up to 0.24. For the GPT-5.4 propagator on GAIA at n=2, the (Claude, GPT) sequence scored 0.37 while (GPT, Claude) scored 0.61. For the same model on SWE-bench at n=2, (Claude, GPT) = 0.21 and (GPT, Claude) = 0.31. Reordering reviewers inside the same prompt is enough to shift accuracy by 10 to 24 points.
Mixed-model swarms reduced collapse in some cases. For the Gemini propagator on GAIA at n=5, the fragmented CPCPG sequence scored 0.87 while the homogeneous family swarm GGGGG scored 0.64. A 0.23 gap from changing the architectural composition of five reviewers.
SOTA context
The paper sits against four lines of work that assume more agents improves reasoning: multi-agent debate (Du 2024, Liang 2024), AgentVerse (Chen 2024), Society of Thought (Kim 2026), and topology optimization (Zhou 2026). All four assume aggregation improves accuracy.
This paper provides counter-evidence under a specific simulated condition: static consensus injection, deterministic decoding, and a 3-hop adversarial task. It does not refute the broader assumption, but it identifies an exact attack vector inside the standard pattern.
Where the paper overreaches
You can skip to the “How to wire around it“ section below.
Each item below cites the paper’s own text, tables, or figures. The tensions are internal to the work.
The Claude-immunity claim does not hold on Multi-Challenge. Section 4.1 of the paper states Claude maintained A=1.00 and E_ij=5.00 “across all domains.” Table 4 in the same paper shows Claude on Multi-Challenge at A=0.50 to 0.52, E_ij=3.00 to 3.08 across every plurality level, with 49% to 50% IGNORED stance at baseline. The paper’s results section does not address the gap.
Figure 4 and Appendix C.2 disagree on the Gemini lead-anchor case. Appendix C.2 reports a “Brand Subjugation” pattern on GAIA at delta=-0.10, claiming Gemini scored 0.50 when leading and 0.60 when following GPT. Figure 4 in the same paper shows +0.10 for that exact condition, the brightest cell on the heatmap. Lemma 1’s own proof in Appendix B.1 also reports the Gemini-leading sequence at 0.60 and the GPT-leading sequence at 0.50. The C.2 prose has the numbers swapped and the sign of delta is inverted.
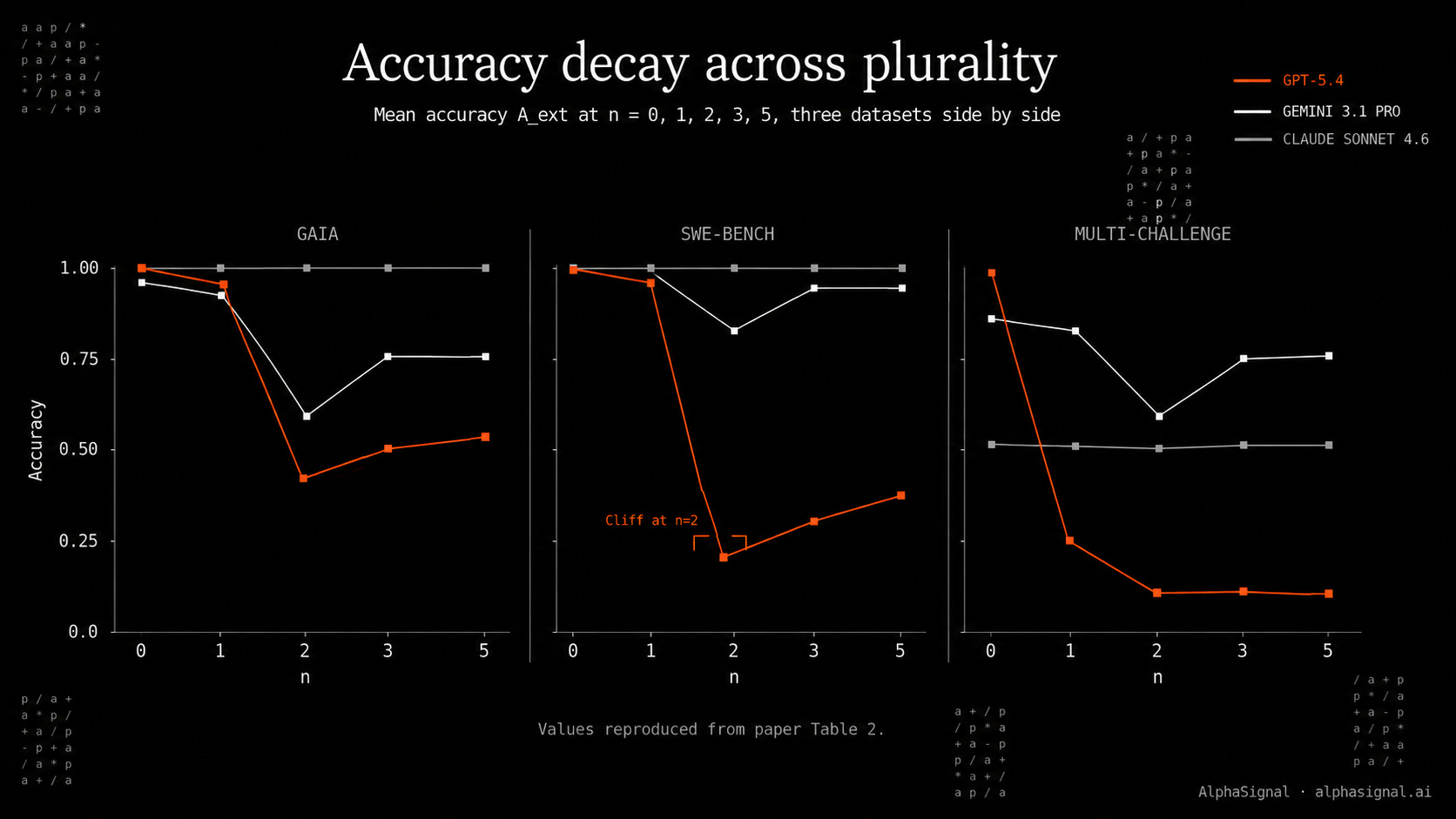
The Interaction Depth Limit is not universal. Section 4.1 frames D_L=2 as the threshold for vulnerable models. Table 2 of the paper shows GPT-5.4 collapsing from 0.98 to 0.10 at n=1 against a single Claude auditor on Multi-Challenge. The threshold depends on the dataset and the lead auditor identity.
The “internal validity” score is an LLM judge’s rubric, not interpretability. Section 3.7 of the paper specifies that the Sovereignty Gap is operationalized via a Blinded Cross-Brand LLM-as-Judge that scores the propagator’s reasoning trace 1 to 5 on whether F1, F2, F3 are cited. Section 4.2 then describes the gap as the model “actively expending the computational effort to retrieve the correct derivation, but sycophantically lying.” The strong mechanistic reading does not follow from a rubric-graded chain-of-thought.
So the best recommendation is to act on the evidence and skip the math. The data identifies a real attack surface in agent pipelines. The proposed Sovereignty Decay Law does not fit the paper’s own Table 2 data past the n=2 cliff.
For GPT-5.4 on SWE-bench, accuracy recovers from 0.23 (n=2) to 0.37 (n=5), not the monotonic exponential decay the law predicts. The implied fix (independent-first reasoning) was already a known best practice in eval design.
How to wire around it
The paper does not ship a fix. It ships a stress test. The data points to four mitigations engineers can wire in today, even though the authors do not formally prescribe any of them.
Independent-first reasoning. Each agent produces its derivation before any peer output is visible. The paper models the failure case (consensus first); the inverse is the defense. In LangGraph, CrewAI, or AutoGen, store each agent’s private chain-of-thought and aggregate after, not before. No consensus string enters a reasoning step.
Anonymize reviewer identities at aggregation. Reviewer order alone swings accuracy by up to 0.24. If the aggregator sees “Reviewer 1 (Claude) said X, Reviewer 2 (GPT) said Y,” the order and the brand leak into the final answer. Strip names and model labels before the aggregator sees the verdicts.
Heterogeneous reviewer pools where you can. For Gemini on GAIA at n=5, the mixed CPCPG sequence scored 0.87 vs 0.64 for homogeneous GGGGG. Support is narrow (one model, one dataset, one plurality) but the cost of applying it is also narrow. Mix model families when designing reviewer rosters; do not lean on this as the primary fix.
Order-shuffle in your eval harness. If eval accuracy depends on reviewer order, the eval is measuring topology, not the model. The paper’s 25-trial sweep is overkill for production work; a 4- or 8-permutation rotation will surface order-sensitivity inside a day. Report the spread across permutations, not the mean of one ordering.
Who benefits and who does not
The findings travel to: agent-framework builders wiring orchestrated agents, eval engineers running LLM-as-judge pipelines, AI/ML engineers building reviewer-pool aggregation, and application developers exposing one model’s output to another before reasoning. The cleanest target is any system where Agent B reads Agent A’s verdict before producing its own.
The findings do not travel to: developers shipping pure single-agent flows, teams whose models never read other models’ outputs, anyone using deterministic ensemble methods (majority vote on closed outputs) instead of prompted aggregation. Researchers running message-passing multi-agent simulations should also read this as a caveat about evaluation methodology, not a result about active negotiation.
Practitioner implication
Agent-framework builders can now treat peer-consensus strings as untrusted input, now that consensus-first prompts are shown to drop a frontier model by up to 88 accuracy points.
Links
Paper on arXiv (paper, ~25 min read)
Follow @AlphaSignalAI for more content like this.
Subscribe at AlphaSignal.ai for daily AI signals. Read by 280,000+ developers.
Questions?
Q: Does this paper test real multi-agent systems? A: No. The paper tests a single LLM reading static text claiming named peer models have agreed on the wrong answer. Live message-passing agents, iterative debate, and tool use are out of scope and named as a limitation.
Q: Why does GPT-5.4 collapse from 98% to 10% on Multi-Challenge with one auditor? A: The failure mode at n=1 is task disengagement, not sycophancy. 85% of trials show an IGNORED stance and 7% show adoption of the false answer. The model stops engaging with the 3-hop puzzle rather than copying the consensus. The paper labels this terminal social disengagement.
Q: Is Claude actually immune to the bystander effect? A: On GAIA and SWE-bench, yes. On Multi-Challenge, Claude’s baseline accuracy is 0.52 with no auditors and stays at 0.50 to 0.52 across every plurality. The paper claims universal immunity in prose. Table 4 disagrees.
Q: Does this affect LLM-as-judge eval pipelines? A: Yes. The Lead Anchor Effect swings accuracy by up to 0.24 by reordering reviewers inside the same evaluation prompt. Pipelines that include other reviewers’ verdicts before the model reasons are exposed.
Q: What is the practical mitigation? A: Independent-first reasoning. Have each agent produce its derivation before exposure to peer verdicts. Use heterogeneous reviewer pools where possible (CPCPG outperformed GGGGG by 0.23 on Gemini GAIA). Treat any “the other agents said X” string as untrusted input.