
Four Agent Orchestration Patterns You Should Know About
How to choose the right multi-agent architecture for cost, accuracy, and scale.

Let’s talk about agent orchestration.
Single-prompt LLM workflows can become difficult to manage once the task grows beyond a simple instruction and response. Context windows still create limits when working with large documents. Complex tasks can increase hallucination risk. Error detection also becomes harder when the system has no built-in verification layer.
This is where multi-agent architectures become useful.
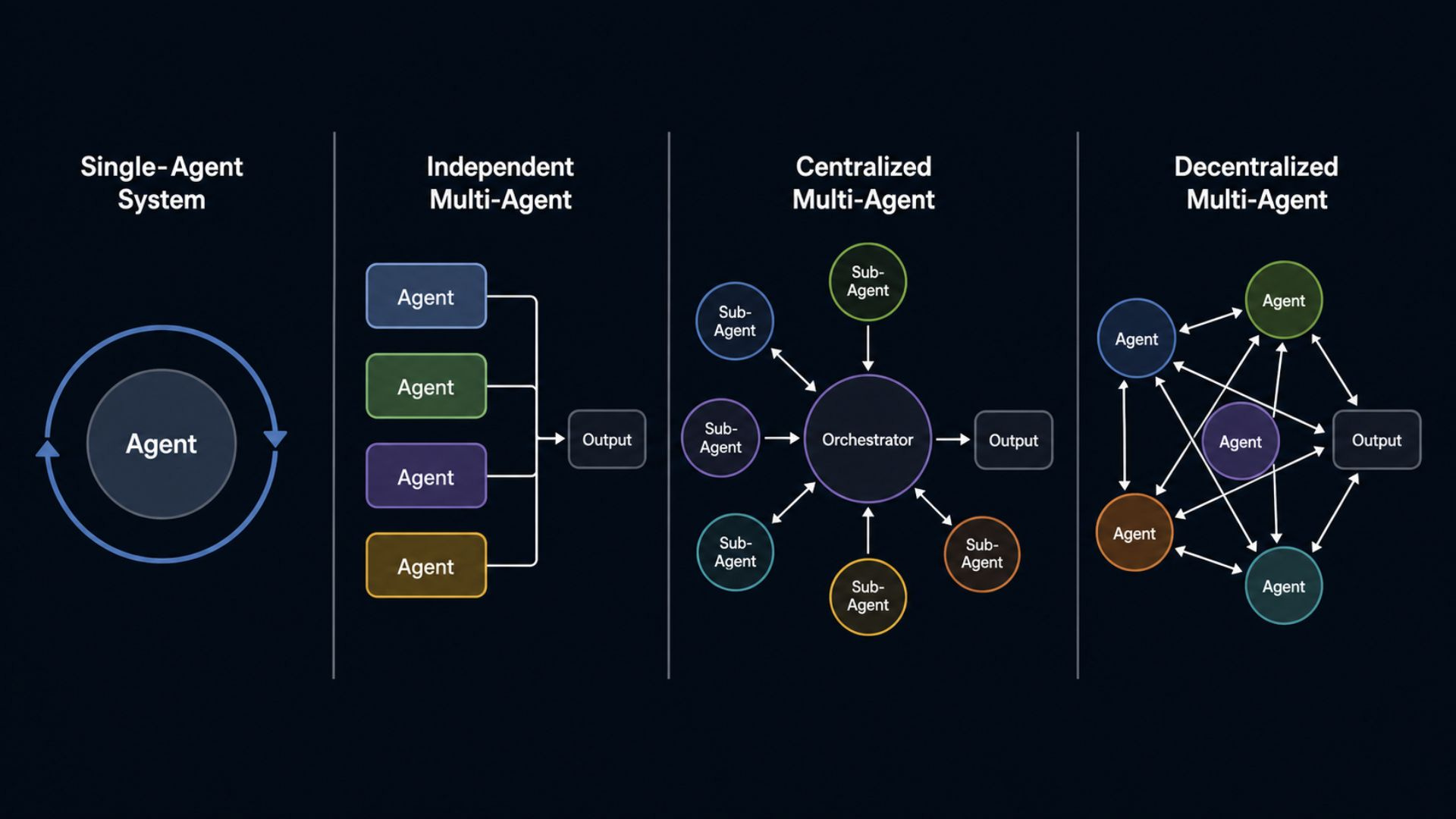
Instead of asking one model to handle everything, you break a large goal into smaller specialized tasks. But adding more agents is not enough by itself. The real design challenge is defining how those agents share state, communicate with each other, verify outputs, and recover from errors.
Siddhant and Yukta Kulkarni from NYU recently published a large benchmark on this problem. They tested 10,000 documents across five frontier and open-weight LLMs and evaluated four orchestration patterns.

The researchers evaluated four multi-agent orchestration architectures:
Sequential pipeline
Parallel fan-out with merge
Hierarchical supervisor-worker
Reflexive self-correcting loop
Each architecture used the same basic set of agents, including a document parser, field extractor, table analyzer, cross-reference resolver, confidence scorer, and output formatter.
The difference was not the agents themselves, but how those agents were connected and coordinated.
Here is a technical breakdown of how each pattern works, where it can fail, and when it makes sense in production.
1. Sequential Pipeline
This is the simplest baseline.
Agents process tasks in a fixed chain. Agent A completes its assigned step and passes the accumulated context to Agent B. Agent B then adds its output and passes everything to Agent C.
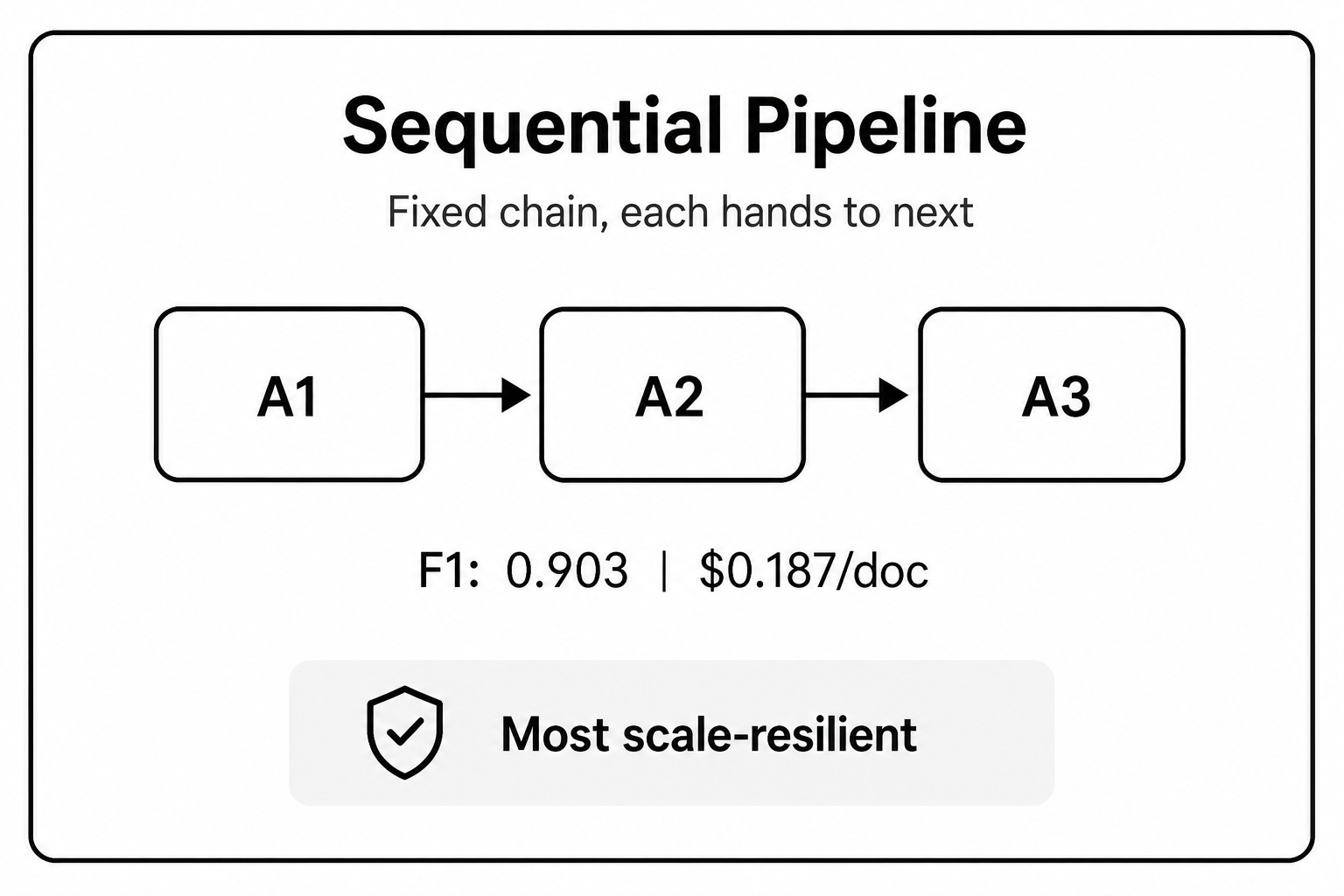
The main advantage is predictability. The execution order is deterministic, and latency scales in a linear way. Since there is no complex coordination between agents, this pattern is highly resilient at scale. When task volume increases to around 100,000 tasks per day, the sequential pipeline shows the smallest drop in accuracy.
The downside is token inefficiency. Every downstream agent has to process the growing context from all previous steps. This means token usage increases as the chain gets longer.
Error propagation is another concern. If the first agent extracts the wrong value or hallucinates a detail, every agent after it inherits that mistake. The system has no natural correction point unless you add one manually.
When to use it: Use this pattern when your tasks are simple, budgets are strict, or you are operating at massive scale. It works best when predictable throughput matters more than peak accuracy.
2. Parallel Fan-Out with Merge
This pattern is designed for speed.
A router sends independent tasks to multiple domain-specific workers at the same time. Once the workers finish, a merge agent collects their outputs and reconciles them into a final result.
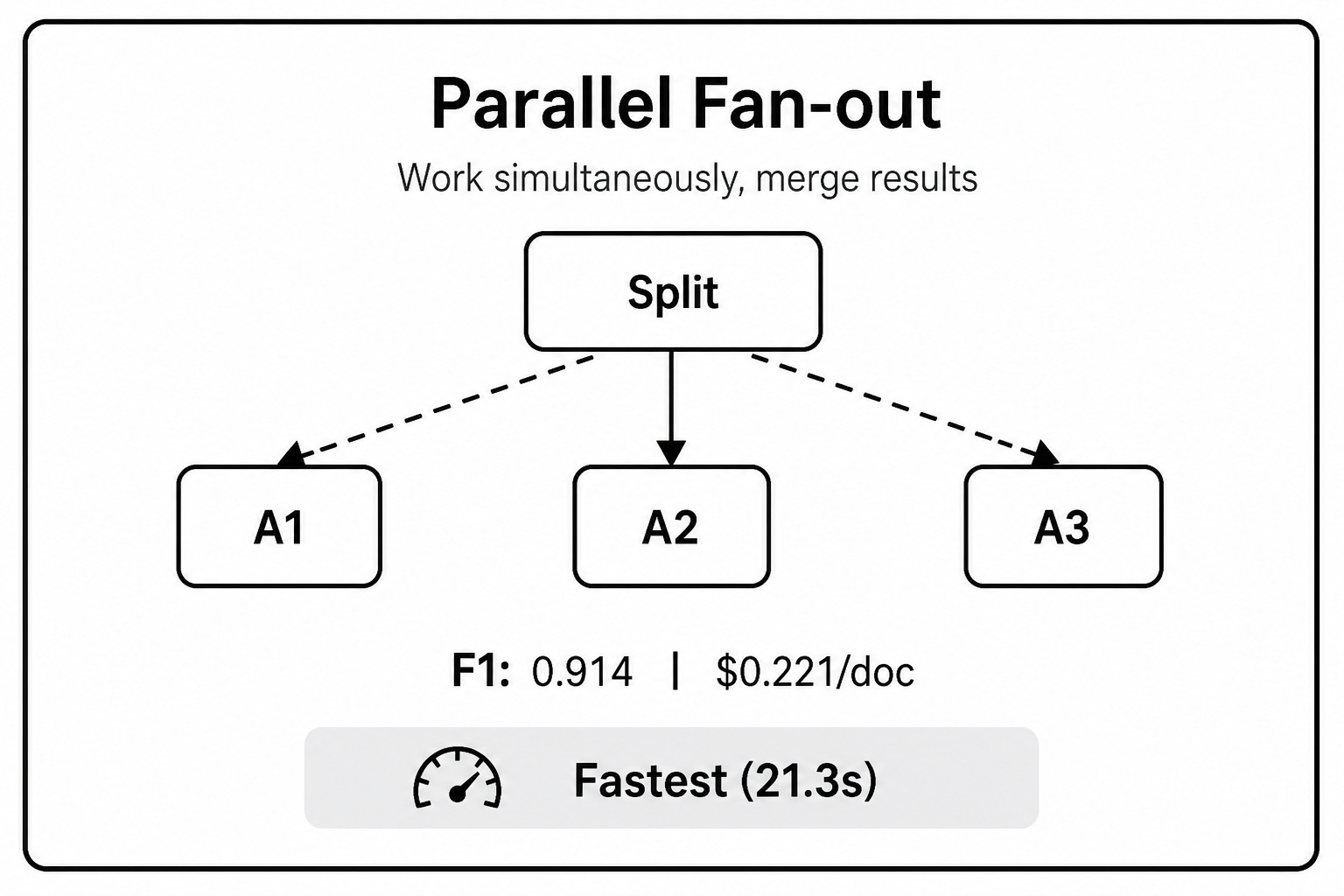
The benefit is lower latency. Since the workers run concurrently, total latency is mostly limited by the slowest branch plus the time needed for the merge step. It also gives you better fault isolation. If one worker fails or produces a bad result, it does not automatically contaminate the other branches.
The trade-off is cost. This is often the least token-efficient architecture of the four. Parallel workers usually need overlapping context to complete their tasks, which means the same input may be processed several times.
The merge step can also become difficult. Independent agents may produce conflicting outputs, incomplete reasoning, or mismatched assumptions. When that happens, the merge agent has to resolve those conflicts without always having enough context to know which answer is correct.
When to use it: Use this pattern when latency is the highest priority or when the tasks are naturally independent. It is a good fit for extraction tasks that do not require shared memory across workers.
3. Hierarchical Supervisor-Worker
This pattern works more like a manager coordinating a specialized team.
A supervisor agent plans the task and assigns specific work to different agents. Each worker returns an output, often with a confidence score. If the confidence score falls below a defined threshold, the supervisor can reassign the task, request a second pass, or escalate it to a stronger model.
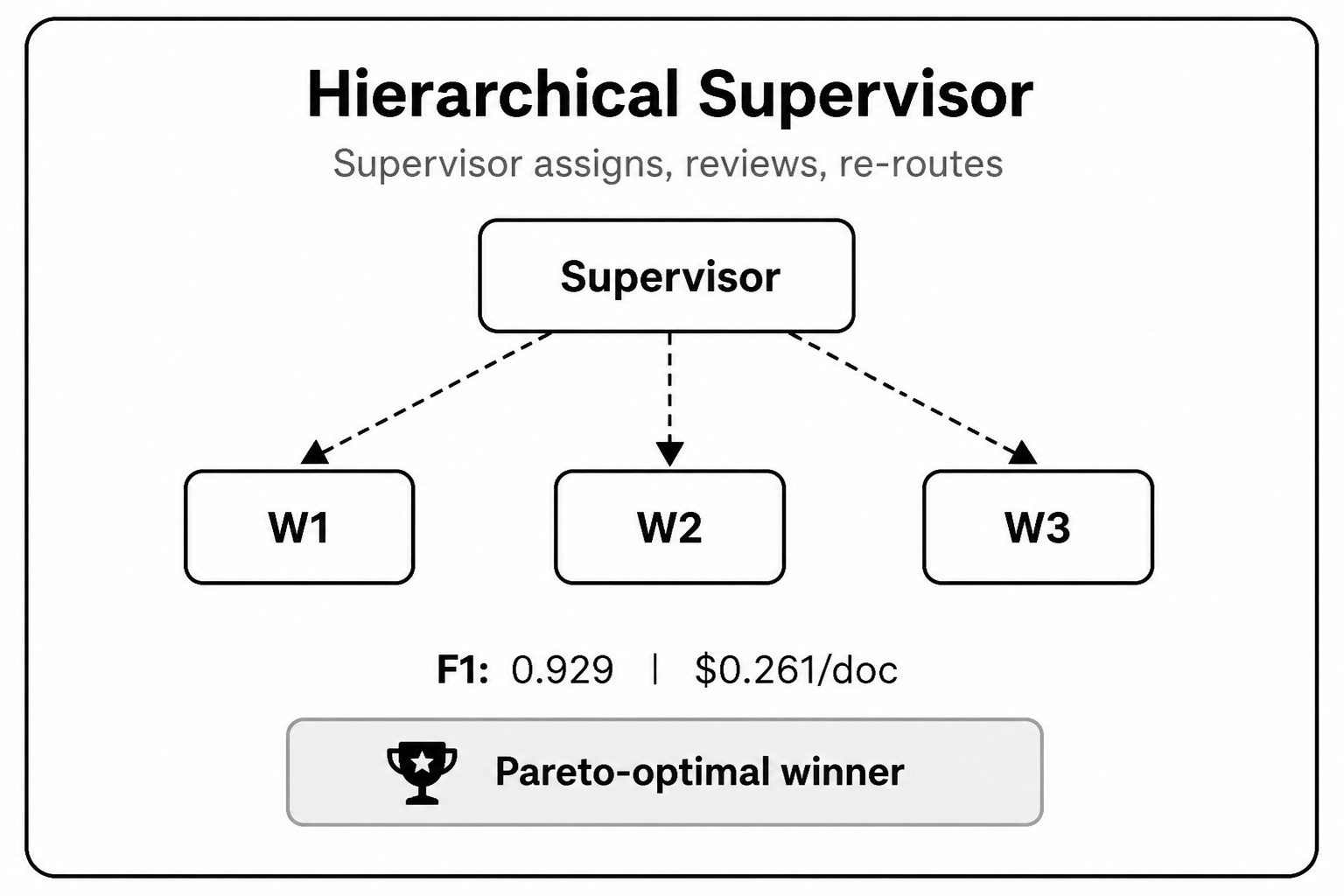
This is usually the most balanced architecture. It reaches 98.5% of the maximum F1 accuracy in the benchmark while costing about 60% of a fully reflexive system.
It is also more token-efficient because workers only receive the context they need. You do not have to send the full accumulated context to every agent. This makes it easier to control cost, especially when the workload has many different task types.
Another advantage is model routing. Simple tasks can be sent to cheaper models, while harder tasks can be escalated to stronger models such as GPT-4o or Claude 3.5 Sonnet. This makes the architecture more flexible for real production systems where cost and accuracy both matter.
The downside is added coordination complexity. The supervisor introduces decision-making latency, and the system becomes more dependent on message passing between agents. If the routing logic is poorly designed, tasks can be assigned incorrectly or agents can fail to return outputs in the expected format.
When to use it: Use this pattern for generalized, moderate-scale production workloads. It is especially useful when you need strong accuracy without letting cost grow out of control.
4. Reflexive Self-Correcting Loop
This pattern relies on explicit verification.
An agent produces an output. A separate verifier reviews it and critiques the result. If the output fails the check, the verifier sends structured feedback back to the original agent for revision. This loop continues until the output passes or the system reaches a fixed iteration limit, often three rounds.
This pattern achieves the highest absolute accuracy in the benchmark. The reason is simple. The system has a built-in mechanism for catching errors, revising weak outputs, and improving the final answer before it reaches the user.
But that accuracy comes with a major cost. The benchmark shows that this pattern can cost up to 2.3 times more than the sequential baseline.
The bigger issue appears at scale. Once this pattern is pushed beyond 25,000 tasks per day, performance starts to degrade. Correction loops create queueing delays. Systems hit timeouts. Some iterations get cut short. Eventually, accuracy can fall below the sequential baseline.
It is also more vulnerable to excessive revision. The system can keep changing its interpretation of ambiguous text instead of settling on the most reasonable answer. In some cases, the correction loop adds complexity without improving reliability.
When to use it: Use this pattern only for low-volume, high-stakes workloads where mistakes are unacceptable and cost is less important. It should not be the default architecture for large-scale production systems.
Performance results
According to the paper, the researchers tested the four orchestration patterns on 10,000 SEC filings using five LLMs: GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Pro, Llama 3 70B, and Mixtral 8x22B.
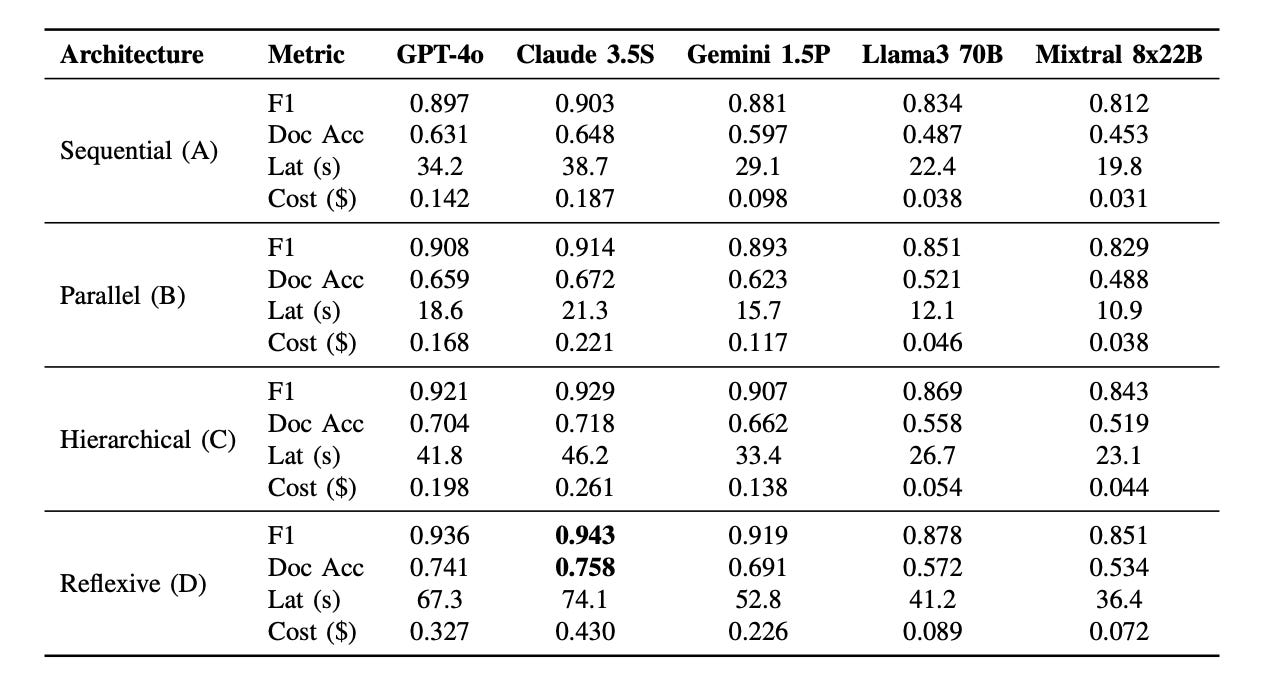
The reflexive self-correcting loop achieved the highest accuracy, reaching 0.943 F1 with Claude 3.5 Sonnet. But it was also the most expensive, costing 2.3 times more than the sequential baseline.
The hierarchical supervisor-worker pattern gave the best balance. It reached 0.929 F1, which is 98.5% of the reflexive score, while costing only 60.7% as much.
Parallel fan-out was the fastest pattern, making it useful when latency matters most.
Sequential pipeline was the cheapest and most stable at large scale, especially when the workload reached up to 100,000 documents per day.
The main takeaway is simple: reflexive wins on accuracy, parallel wins on speed, sequential wins on cost and scale, and hierarchical is the best default choice for most production workloads.
Which Pattern Should You Choose?
The right orchestration pattern depends on what you are trying to optimize.
If you are working at massive scale or need the lowest possible cost, use a sequential pipeline.
If real-time speed is the main requirement, use parallel fan-out with merge.
If accuracy is the top priority and the workload volume is low, use a reflexive self-correcting loop.
For most enterprise workloads, the hierarchical supervisor-worker pattern is the safest default choice. It gives you a cleaner balance between accuracy, cost, latency, and operational control.
A separate study of 70 real-world agent projects also raised an important warning: stronger models do not automatically create safer or more reliable systems.
Paper => https://arxiv.org/abs/2604.18071
The architecture around the model plays a huge role. A pattern that looks impressive in a small demo can become expensive, slow, or unstable once it is pushed into production.
That is why the simpler choice is often the better starting point. Use the least complex pattern that can handle the workload. Add hierarchy when you need smarter routing. Add reflexive verification only when the risk is high enough to justify the extra cost.
In production, agent orchestration is not just about making agents work together. It is about designing the system around the real limits of the workload: cost, latency, accuracy, scale, and failure recovery.
Are you currently planning an architecture for a specific workload where we could apply one of these patterns?
Follow @AlphaSignalAI for more content like this.
Check out http://AlphaSignal.ai to get a daily summary of top models, repos, and papers in AI. Read by 280,000+ devs.